Pentaho Data Integration: Designing a highly available scalable solution for processing files
Tutorial Details
- Knowledge: Intermediate (To follow this tutorial you should have good knowledge of the software and hence not every single step will be described)
Preparation
The raw data generated each year is increasing significantly. Nowadays we are dealing with huge amounts of data that have to be processed by our ETL jobs. Pentaho Data Integration/Kettle offers quite some interesting features that allow clustered processing of data. The goal of this session is to explain how to spread the ETL workload across multiple slave servers. Matt Casters originally provided the ETL files and background knowledge. My way to thank him is to provide this documentation.
Note: This solutions runs ETL jobs on a cluster in parallel independently from each other. It's like saying: Do exactly the same thing on another server without bothering what the other jobs do on the other servers. Kettle allows a different setup as well, where ETL processes running on different servers can send i.e. the result set to a master (so that all data is combined) for sorting and further processing (We will not cover this in this session).
Preparation
Download the accompanying files from here and extract them in a directory of your choice. Keep the folder structure as is, with the root folder named ETL. If you inspect the folders, you will see that there is:
- an input directory, which stores all the files that our ETL process has to process
- an archive directory, which will store the processed files
- a PDI directory, which holds all the Kettle transformations and jobs
Create the ETL_HOME variable in the kettle.properties file (which can be found in C:\Users\dsteiner\.kettle\kettle.properties)
ETL_HOME=C\:\\ETL
Adjust the directory path accordingly.
Navigate to the simple-jndi folder in the data-integration directory. Open jdbc.properties and add following lines at the end of the file (change if necessary):
etl/type=javax.sql.DataSource
etl/driver=com.mysql.jdbc.Driver
etl/url=jdbc:mysql://localhost/etl
etl/user=root
etl/password=root
Next, start your local MySQL server and open your favourite SQL client. Run following statement:
CREATE SCHEMA etl;
USE etl;
CREATE TABLE FILE_QUEUE
(
filename VARCHAR(256)
, assigned_slave VARCHAR(256)
, finished_status VARCHAR(20)
, queued_date DATETIME
, started_date DATETIME
, finished_date DATETIME
)
;
This table will allow us to keep track of the files that have to be processed.
Set up slave servers
For the purpose of this exercise, we keep it simple and have all slaves running on localhost. Setting up a proper cluster is out of this scope of this tutorial.
Kettle comes with a lightweight web server called Carte. All that Carte does is listen to incoming job or transformation calls and process them. For more info about Carte have a look at my Carte tutorial.
So all we have to do now is to start our Carte instances:
On Windows
On the command line, navigate to the data-integration directory within your PDI folder. Run following command:
carte.bat localhost 8081

Open a new command line window and do exactly the same, but now for port 8082.
Do the same for port 8083 and 8084.
On Linux
Open Terminal and navigate to the data-integration directory within your PDI folder. Run following command:
sh carte.sh localhost 8081
Proceed by doing exactly the same, but now for ports 8082, 8083 and 8084.
Now that all our slave servers are running, we can have a look at the ETL process ...
Populate File Queue
Start Kettle (spoon.bat or spoon.sh) and open Populate file queue.ktr (You can find it in the /ETL/PDI folder). If you have Kettle (Spoon) already running, restart it so that the changes can take effect and then open the file.
This transformation will get all filenames from the input directory (of the files that haven't been processed yet) and stores them in the FILE_QUEUE table.
Double click on the Get file names step and click Show filename(s) … . This should show all your file names properly:

Click Close and then OK.
Next, double click on the Lookup entry in FILE_QUEUE step. Click on Edit next to Connection. Then click Test to see if a working connection can be established (the connection details that you defined in the jdbc.properties file will be used):

Click 3 times OK.
Everything should be configured now for this transformation, so hit the Play/Execute Button.
In your favourite SQL Client run following query to see the records that were inserted by the transformation:
SELECT
*
FROM
FILE_QUEUE
;

Once you inspected the results run:
DELETE FROM FILE_QUEUE ;
The idea is that this process is scheduled to run continuously (every 10 seconds or so).
Define Slave Servers
First off, we will create a table that stores all the details about our slave servers. In your favourite SQL Client run following statement:
CREATE TABLE SLAVE_LIST
(
id INT
, name VARCHAR(100)
, hostname VARCHAR(100)
, username VARCHAR(100)
, password VARCHAR(100)
, port VARCHAR(10)
, status_url VARCHAR(255)
, last_check_date DATETIME
, last_active_date DATETIME
, max_load INT
, last_load INT
, active CHAR(1)
, response_time INT
)
;
Open the Initialize SLAVE_LIST transformation in Kettle. The transformation allows to easily configure our slave server definition. We use the Data Grid step to define all the slave details:
- id
- name
- hostname
- username
- passoword
- port
- status_url
- last_check_date: keep empty, will be populated later on
- last_active_date: keep empty, will be populated later on
- max_load
- last_load: keep empty, will be populated later on
- active
- response_time: keep empty, will be populated later on

As you can see, we use an Update step: This allows us to basically change the configuration at any time in the Data Grid step and then rerun the transformation.
Execute the transformation.
Run following statement in your favourite SQL client :
SELECT * FROM SLAVE_LIST ;
Monitor Slave Servers
Features:
- Checks the status of the active slave servers defined in the SLAVE_LIST
- Checks wether they are still active
- Calculates the load (number of active jobs) per slave server
- Calculates the response time
Open following files in Kettle:
- Slave server status check.kjb
- Get SLAVE_LIST rows.ktr: Retrieves the list of defined slave servers (including all details) and copies rows the to the result set
- Update slave server status.kjb: This job gets executed for each input row (=loop)
- Set slave server variables.ktr: receives each time one input row coming from the result set of Get SLAVE_LIST rows.ktr and defines variables for each field, which can be used in the next transformation
- Check slave server.ktr:
- Checks whether the server is not available or status is 200 and then updates the SLAVE_LIST table with an inactive flag and last_check_date.
- If the server is available:
- it extracts the amount of running jobs from the xml file returned by the server
- keeps the response time
- sets an active flag
- sets the last_check_date and last_active_date (both derived from the system date)
- updates the SLAVE_LIST table with this info
Please find below the combined screenshots of the jobs and transformation:
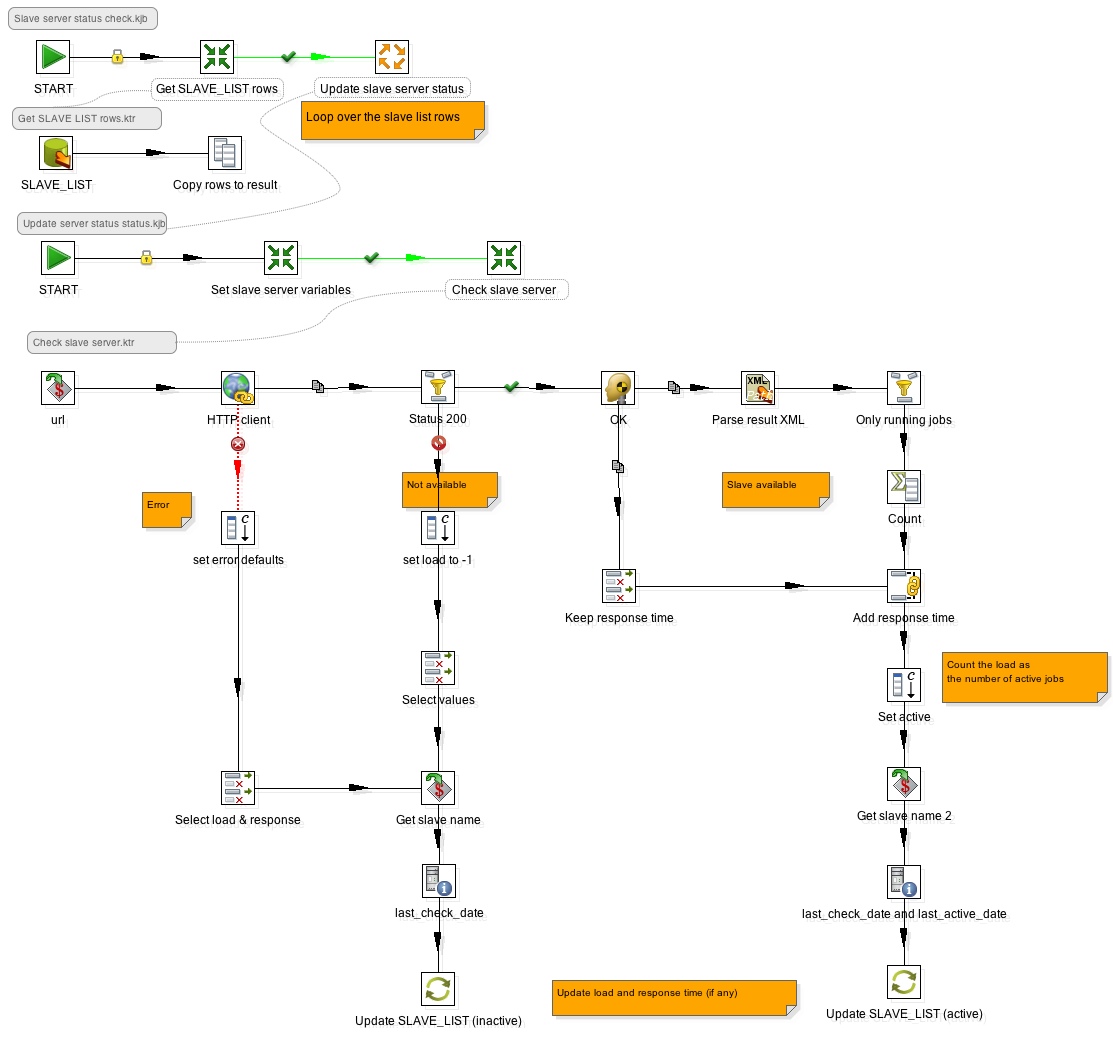
So let's check if all our slave servers are available: Run Slave server status check.kjb. Run the following statement in your favourite SQL client:
SELECT * FROM SLAVE_LIST;
The result set should now look like on the screenshot below, indicating that all our slave servers are active:

Distribution of the workload
So far we know the names of the files to be processed and the available servers, so the next step is to create a job that processes one file from the queue on each available slave server.
Open Process one queued file.kjb in Kettle.
This job does the following:
- It checks if there are any slave servers available that can handle more work. This takes the current and maximum specified load (the number of active jobs) into account.
- It loops over the available slave servers and processes one file on each server.
- In the case that no slave servers are available, it waits 20 seconds.

Some more details about the job steps:
- Any slave servers available?: This fires a query against our SLAVE_LIST table which will return a count of the available slave servers. If the count is bigger than 0, Select slave servers is the next step in the process.
- Select slave servers: This transformation retrieves a list of available slave servers from the SLAVE_LIST table and copies it to the result set.
- Process a file: The important point here is that this job will be executed for each result set row (double click on the step, click on the Advanced tab and you will see that Execute for each input row is checked).
Open Process a file.kjb.

This job does the following:
- For each input row from the previous result set, it sets the slave server variables.
- It checks if there are any files to be processed by firing a query against our FILE_QUEUE table.
- It retrieves the name of the next file that has to be processed from the FILL_QUEUE table (a SQL query with the limit set to 1) and sets the file name as a variable
- It updates the record for this file name in the FILE_QUEUE table with the start date and assigned slave name.
- The Load a file job is started on the selected slave server : Replace the dummy Javascript step in this job with your normal ETL process that populates your data warehouse. Some additional hints:
- The file name is available in the ${FILENAME} variable. It might be quite useful to store the file name in the target staging table.
- In case the ETL process failed once before for this file, you can use this ${FILENAME} variable as well to automatically delete the corresponding record(s) from the FILE_QUEUE table and even the staging table prior to execution.
- Note that the slave server is set in the Job Settings > Advanced tab:
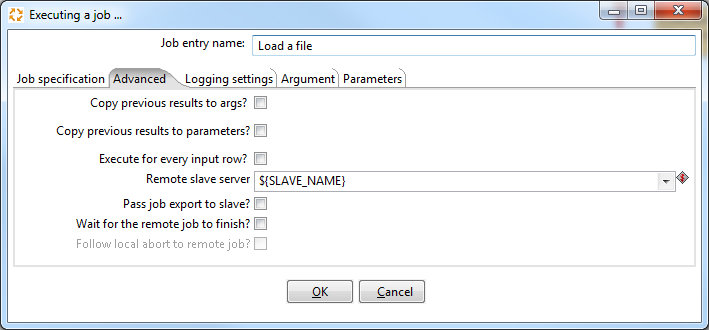
- If the process is successful, the record in the FILE_QUEUE table gets flagged respectively. The same happens in case the process fails.
Test the whole process
Let's verify that everything is working: Open Main Job.kjb in Kettle and click the Execute icon.
Now let's see if 4 files were moved to the archive folder:

This looks good ... so let's also check if our FILE_QUEUE table has been updated correctly. Run following statement in your favourite SQL client:

Note that the last file (file5.csv) hasn't been processed. This is because we set up 4 slave servers and our job is passing 4 files to each of the slave servers. The last file will be processed with the next execution.
Thanks for blogging about this job Diethard!
ReplyDeleteYou did a great job and I hope it will be inspiring for other folks to extend this framework.
Cheers,
Matt
Thanks a lot Matt! Much appreciated!
ReplyDeleteIt's very nice to see more operational things around Kettle like this.
ReplyDeleteNice one, and just in time too! I'm myself busy going through various iterations trying to find the ideal operational scheme to load data from sources.
ReplyDeleteI normally add a 'flag file' that contains information about the files to be processed. The flag file is provided by the data supplier, and would look like this example:
----------------------------
file1.csv
file2.csv
--fin--
----------------------------
The existing of the flag file, and the presence of the terminating line '--FIN--' is used to prevent half transferred file from being processed, especially large ones.
Thanks for your feedback! Yes, you mention an important point here: Processing partially transferred csv files has to be avoided.
ReplyDeletePlease change the db access in ark file finished in queue.ktr Update FILE_QUEUE step to the JNDI value to get the system to work out of the box.
ReplyDeleteThanks a lot for pointing this out! I updated the file. This new version is now available for download.
ReplyDeleteAbsolutely amazing! - Thanks for creating this.
ReplyDeleteHi Diethard,
ReplyDeleteI just started looking into your transformations and job and the concept looks great. I downloaded the code but I am facing issues while trying to run the job Slave servers status check. The error is happening in the transformation Check slave server saying that response_time is not present in the row. I added that field in response_time to Add constant step set load to -1 and added a Add constant step(with just one field response_time) just before Keep Response Time select values step in the next track. I gave -1 as values to them. That made the transformation working. But I didn't understand what you have meant by response_time field and I am not clear with that what I have done as well. Can you help me in understanding that.
Many Thanks in advance.
Hi,
ReplyDeleteThe response_time field gets generated in the HTTP client step. This one basically tries to call your carte slave server. So either the step settings are not properly configured, or the variables are not properly passed on (${SLAVE_USERNAME} and all the other ones in the url step).
I would test first if the variable is passed on properly, because if no Carte slave server is running, the process flow should follow the Error branch, which automatically sets response_time to -1.
I suggest testing the transformation on its own. Supply the variables in the transformation settings (CTRL+T) and assign values to them, then run the transformation and see where it goes wrong. (Don't forget to remove the variables from the transformation settings after testing). I hope this helps.
Hi Diethard,
ReplyDeleteThank you so much for your quick response. I think my PDI version is the problem. I am using 4.0.1 and I think the response_time is not included in this version HTTP_CLIENT step I guess. I tried the way you mentioned but it is still showing the same error. I will try this in a newer version and will let you the status.
Also I have another question of Carte. What is best way to start Carte service in a production environment? Is it possible to implement this as a service with start, stop and restart facility? Also while I was playing with some simple clustered transformation I found that some times there occurs a caching kind of think, where the old transformation gets submitted to the slaves and master instead of the new modified one. At those stages I had to stop and restart the carte and run the transformation. Can you give me some inputs related to these kind of issues?
If you see some problems in the way Carte is behaving, it is best you set up a JIRA case on jira.pentaho.com. But first of all I advise you use a recent version of PDI.
ReplyDeleteAlso, if you want a start, stop and restart facility, please submit a request for this on the JIRA website as well.
Hi Diethard,
ReplyDeleteSorry for the delay in my replay. I was help up with some urgent task these days. I got the Job running in my latest PDI version. The problem was with my old version HTTP_Client step which didn't had the response_time field option.
I executed the job as per your example and I got the first 4 files processed in the first run. I had started 4 Carte instances in four different port but while execution only 3 carte servers where used. Ie at port 8082 two files got executed and 8084 port was unused. But as per the file_queue table we have four carte servers assigned to first four files. What could be the reason for this?
Also what I understood from executing job/transformation for each input row option is that it will be creating a sequential loop. Or is that a parallel triggering? ie Will the file process job be triggered in parallel. Ie if I have four transformation where each one takes 10 mins for execution, will this four transformation run in parallel in four different carte instances? So in practical terms will I get the four transformations executed in say 12 or 13 mins instead of 4x10 = 40 mins?
I can have the Dummy Javascript step in Load a file job replaced with my required transformation step, correct?
Many thanks in advance for your replies.
Regards,
Sunil George.
Hi Sunil,
ReplyDeleteThe idea is that all of them are executed in parallel. All Carte instances should be used unless there is an error. The slave_list table should tell you how many instances are available.
"I can have the Dummy Javascript step in Load a file job replaced with my required transformation step, correct?"
Yes, exactly.
Best regards,
Diethard
Very Nice walk through and samples..Thanks a lot
ReplyDeleteRegards,
Gururaj
Thanks a lot for your feedback! Much appreciated!
ReplyDeleteHi dietheard,
ReplyDeletefirst of all thanks alot for your detailed blog. It helped alot.
I run jobs through kitchen. but I dont see any option to set it to execute remotely. can you tell me how can I do that?
thanks
-vishal
Hi Vishal. Is your comment regarding "Pentaho Data Integration: Designing a highly available scalable solution for processing files" or is this a general question?
ReplyDeleteI got it working. I wanted to submit jobs to carte server through kitchen.bat. I did this
ReplyDeleteJob Xml changes are required to tell kettle to run the job and transformations on remote server.
Slave Server entry is needed to add in the Jobs xml/kjb. below is the example of it. I have also attached image to determine slave server entries.
I am happy to hear you got the process working. You do not have to define slave server entries in the job file. All the slave details get passed in dynamically, so there shouldn't be a need for this.
ReplyDeletecurios question, my scenario is I have one huge file and cannot be split in different files, how is the processing/transformation of the file will happen, will it be split on the fly and distribute the task on each slave server?
ReplyDeleteNo, if you deliver one file, it will be only reading this one file in one go.
ReplyDeleteHi Diethard,
ReplyDeleteThanks a lot for implementing Parallel process in Pentaho. In above process, I would like to know how to execute more than 4 files in one loop using current 4 slaves only.
Current Code Behavior:
If there are 10 files in queue to process, but the job will end after archiving 4 files.
But In File_Queue there will be some more files available to process. I would like to process entire files (10files) at one shot.
Thanks.
Hi Yuvakesh,
DeleteThanks for your feedback! You mainly have to thank Matt Casters for this! The above job should process all your files, not just 4 of them (at least at the time I wrote this tutorial it did).
Best regards,
Diethard
Thanks for quick replay Diethard!!
ReplyDeleteThe above process can process only 4 files each for slave and the remaining files shall be processed in next run. Even you have mentioned that in above tutorial at last 2 lines.
Kindly let me know how to process more than 10 files in one execution by using 4 slaves only.
Thanks!
Ok, I had a look at this. It's a long time ago I wrote this, so actually, you were correct, the job will only process 4 files. You can certainly improve this so that it loops over the remaining files.
DeleteYuvakesh,
DeleteDid you find some way out to process all 10 files in loop using 4 carte servers ?
Hi Diethard,
ReplyDeleteThe screenshots and attachment on this post seem to be missing. Are they recoverable?
Kind regards,
Dave
Thanks for letting me know! No too sure what happened ... I will try to find some time this weekend to fix this.
DeleteHi Diethard,
ReplyDeleteI run this job in loop for a bulk of 63,000 files and i am facing following exception in the job "Process one queued file per available slave" Can you please give any suggestions on it?
2013/11/29 16:51:17 - Get filename and slave.0 - Finished processing (I=0, O=0, R=1, W=1, U=0, E=0)
2013/11/29 16:51:17 - started_date.0 - Finished processing (I=0, O=0, R=1, W=1, U=0, E=0)
2013/11/29 16:51:17 - Update FILE_QUEUE.0 - Finished processing (I=1, O=0, R=1, W=1, U=1, E=0)
2013/11/29 16:51:17 - Process a file - Starting entry [Load a file]
2013/11/29 16:51:19 - Load a file - ERROR (version 4.3.0-stable, build 16786 from 2012-04-24 14.11.32 by buildguy) : Error running job entry 'job' :
2013/11/29 16:51:19 - Load a file - ERROR (version 4.3.0-stable, build 16786 from 2012-04-24 14.11.32 by buildguy) : org.pentaho.di.core.exception.KettleException:
2013/11/29 16:51:19 - Load a file - ERROR (version 4.3.0-stable, build 16786 from 2012-04-24 14.11.32 by buildguy) : java.lang.NullPointerException
2013/11/29 16:51:19 - Load a file - ERROR (version 4.3.0-stable, build 16786 from 2012-04-24 14.11.32 by buildguy) : at java.lang.Thread.run (null:-1)
2013/11/29 16:51:19 - Load a file - ERROR (version 4.3.0-stable, build 16786 from 2012-04-24 14.11.32 by buildguy) : at org.pentaho.di.job.entries.job.JobEntryJobRunner.run (JobEntryJobRunner.java:68)
Regards,
Fatima.
Hi Matt and Diethard,
ReplyDeleteI followed your above mentioned ETL tutorial as it is and it works quite well as you mentioned. Following are some of my findings which should must be discussed with you guys.
(PC Specs: 3.4 GHz Core i7, 8GB RAM)
1. I ran your model with ~30,000 csv files (1KB-1000KB, 21 columns) it returned the same Exception as mentioned above by Fatima
2. I modified it to read a csv file and directly dump into a MySql table. Parallelism is being achieved and so is scalability but is much slower than sequential csv loading into database
3. When the solution is run in a loop ("Process one queued file per available slave" to "Dummy" to "Slave servers status check"). It keeps on assigning slave server to the last group even if finished status is OK. In your 5 files group. It keeps on assigning a slave server to 5th file
4. When ran in same above loop slave server assignment is in order of Slave1, Slave2,Slave3, Slave4 irrespective of csv file size!
Thanks for your feedback and sharing your experience! As always, there is room for improvement ... consider this as an example only.
DeleteThanks Diethard for your quick response. Noted your point! It would be super cool if Matt Casters tries to optimize this model.
DeleteBest,
Kanwar Asrar Ahmad
I was trying to say that it is down to the data integration/ETL developer to further improve this model. Consider this as a starting point, there are certainly a few more things you can improve. If something that you want to do is not possible with today's Kettle version, then you can submit a feature request on jira.pentaho.org.
DeleteI am interested to see how people have extended this framework. The adoption rate of hadoop has me working with files at an increased pace. In one particular project I am creating additional hadoop optimized files from the original (avro, orc, etc)
ReplyDeleteThe latest version of PDI has support for YARN. This might be EE only though.
Delete