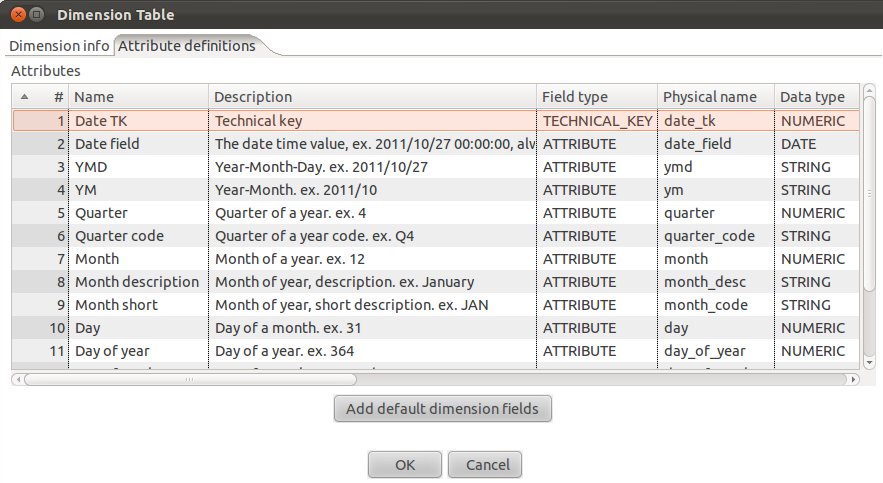
Together we are stronger: Pentaho Data Integration and Pentaho Report Designer for total flexibility
In this section I will try to highlight future potential of a metadata driven approach. Currently the tools don't have all the necessary features, hence I will point out at the end what new features should be ideally added.
Metadata driven ETL
Now that we know how to set up a metadata driven report, we can have a look at creating a metadata driven ETL process to supply data to our metadata driven report template.
PDI (Kettle) only recently received a new transformation step called ETL Metadata Injection. The idea is to have one transformation that acts as a metadata injector to the main transformation. This main transformation is a skeleton of an ETL process: All the steps are defined, but not all or most of the metadata.
Currently not all transformation steps support metadata injection. Find below a list of steps that currently work with the ETL Metadata Injection step (status: July 2011):
CSV Input
Excel Input
Select Values
Row De-normalizer
Row normalizer
So right now, the possibilites are quite limited, but this list will be growing over time as people start submitting requests on the Pentaho JIRA website. So if you already have an idea as to which transformation step should have metadata injection support, visit the aforementioned website and submit a JIRA feature request (ideally check first if there is not already one set up).
If you use the Metadata Injector step and point it to the main transformation, it will show which steps are supported.
As Matt Casters put it: "The golden rule is: if the step doesn't show up, it's not supporting metadata injection yet".
We will be looking at an extremely simple example (tr_metadata_injection_main.ktr):
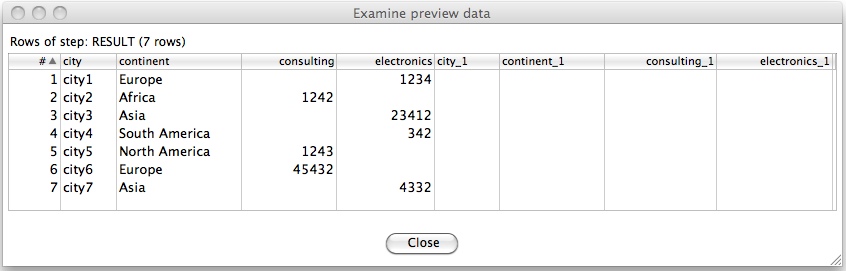
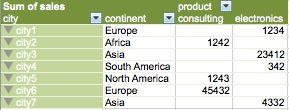
Image in we have a dataset which looks like this one:

Our ETL process should pivot this data in this way:
Now if our original dataset contains only a static number of product names (in our case: electronics, consulting), then we can easily set up a predefined ETL process. But what if the number of product names might change in future?
So far we only had the option to amend our ETL process manually, which means we had to edit our Kettle transformation and add the new name(s) to the Row denormalizer step. This was rather inconvenient as ideally this should have been picked up automatically. The great news is, that now this is possible with the ETL Metadata Injection step.
Create following table on your database of choice (amend if necessary):
USE
test
;
CREATE TABLE
product_sales
(
city VARCHAR(20),
continent VARCHAR(20),
product VARCHAR(20),
sales INT(255)
)
engine=innodb
;
INSERT INTO
product_sales
VALUES
("city1","Europe","electronics",1234),
("city2","Africa","consulting",1242),
("city3","Asia","electronics",23412),
("city4","South America","electronics",342),
("city5","North America","consulting",1243),
("city6","Europe","consulting",45432),
("city7","Asia","electronics",4332)
;
Now let's create our transformation based on the screenshot below:

This transformation will query data from the table we just created. The Select values step allows use to keep only the required fields (It's not really useful in this example, but mainly here for demonstration purposes). Next the data goes into the Row denormalizer step, which basically pivots our data.
To test this transformation I suggest adding a Text file output step and filling out all the required settings in all the steps. Once this works, change the settings of the relevant steps and hops so that they look like the ones shown in the screenshot above. As you can see, we leave the Select values step completely unconfigured and for the Row denormalizer step we only define the Key and Group by fields. Everything else we will configure by using the ETL Metadata Injection step.
We create a second transformation (tr_metadata_injection_config.ktr) to supply the metadata to our main transformation:
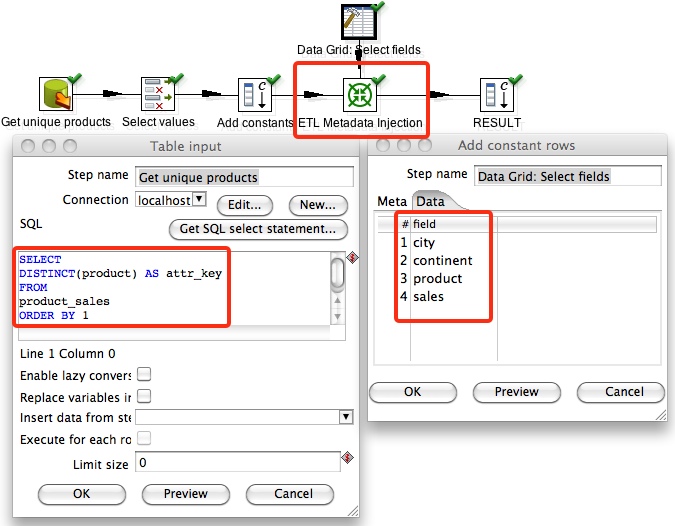
First off we have to get the unique product names in order to pivot the data correctly. We use a Table input step therefore with following query:
SELECT
DISTINCT(product) AS product
FROM
product_sales
;
For this stream we also add some additional fields to have all the metadata complete for injection to the Row denormalizer step in our original transformation.
We also use a Data Grid step to define the fields that we want to keep for the Select values step in our original transformation.
Now we can map our metadata with the steps of our original transformation:
Double click on the ETL Metadata Injection step and the settings dialog will pop up.
Click the Browse button to choose which transformation you want to inject metadata to.
Click Ok, then double click again on the ETL Metadata Injection step and you will see a tree-like representation of your main transformation. For each step you see all the settings that can be used by the metadata injection. You do not have to provide all of them though, but definitely the essential ones. If you are unsure as to what the essential once are, then just create a separate testing transformation and test which settings are necessary for a certain step to work properly.
For the settings that you want to provide metadata for, click on the Source step field in the respective row and a dialog will guide you through the mapping:

As we want to use the output of our original transformation in this current transformation, we also define the Row denormalizer step as Source step to read from (optional).
The last step Results (Add constant values step) is a hack: Currently there is no way to pass on the dynamic results of the ETL metadata injection to PRD.