Talend Open Studio: How to set up context variables
A common concept of making your ETL process easy to configure is to use global variables. This caters for scenarios when you have to move your ETL processes from development to testing and then to production. The idea is to change a few variable values in a central file and then your ETL process will already run on another environment: What a time saver!In this tutorial we will take a look at how to achieve this with Talend Open Studio for Data Integration.
Common global variables
First let’s have a look at settings that we would like use a variable for:Database details:
source_database
source_username
source_password
source_port
source_schema
source_server
target_database
target_username
target_password
target_port
target_schema
target_server
reject_database
reject_username
reject_password
reject_port
reject_schema
reject_server
logging_database
logging_username
logging_password
logging_port
logging_schema
logging_server
ETL job execution:
date_start
date_end
temp_data_dir
source_dir
The above are just examples, there are many more use cases.
How to create global variables
Talend has the concept of context variables. You can access them in the settings fields by pressing CTRL+SPACE.In Talend Open Studio you can create several context groups which hold various variables.
Think of context groups as a bucket for related variables. For each context group you can define various contexts like production, devolpment, test etc. This is extremely useful when moving your ETL jobs from one environment to the other.
Note: You can create as many context groups as you want. Currently, every time you create a context group, you have to define the contexts as well. I added a new feature request which will allow you to define the contexts once in the project settings so that each time when you create a new context group these contexts are assigned by default. This should help to keep the contexts more consistent and manageable across multiple context groups.
To create new variables, right click on Contexts in the repository and choose Create context group:

First create the variables by pressing the + button and assign it a type:
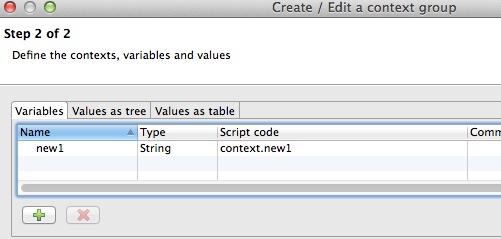
Then click on the Value as tree tab and expend your variable definition. Note that the default context will be called default. To change this name and/or to add other contexts, click on the context icon on the top right hand corner:

The Configure Contexts dialog allows you to edit existing contexts or to add new ones. Once you defined your contexts, click OK.
Now you will see your new/altered context show up in the main dialog. Define if you want a prompt and prompt text for each variable/context combination. Finally define a value:
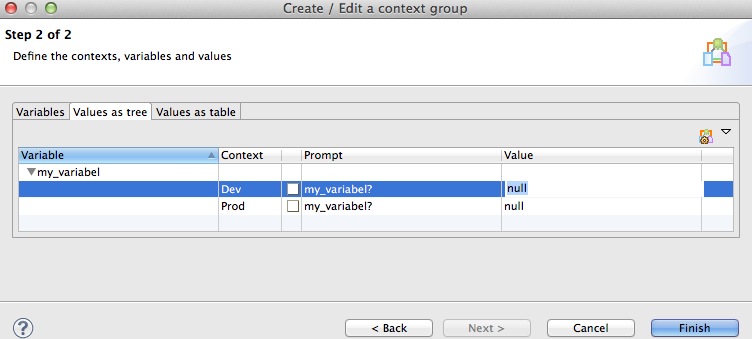
When you are done, click on Finish.
Specifying the variables this way allows you to use them across multiple jobs. Think of it as an approach to easily manage your variables across all your jobs. You can create variables for each job as well, but these ones will local to that job only (and hence not be available for other jobs).
How to use repository context variables within jobs
Once you have the context variables defined in the repository, you can easily add them to your job:- Open the job and click on the Context tab. Then click on the Repository icon:
- Select the variable you want to add and click OK.
- These variables will now show up in the context tab. Note that the variable will be available with the context prefix:



Here two examples on how to use the variables in a query:
"SELECT * FROM raw_data WHERE date>= DATE '"+context.date_start+"' AND date<= DATE '"+context.date_end+"'"
"SELECT * FROM raw_data WHERE date>= TO_DATE('"+context.date_start+"','yyyyMMdd') AND date<= TO_DATE('"+context.date_end+"','yyyyMMdd')"
And here you can see an example using a context variable to define part of the file path:

How to define the context on execution
While designing you job, you can choose the context from the Run tab: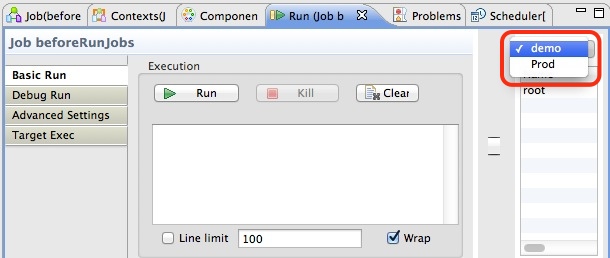
When you export your job, you will also have an option to specify the context.
How to load context variables dynamically
You can use the tContextLoad component to load the variables dynamically in example from a file when you run the jobs with different environments (See forum question for details).Easily setup context variable for your connection
When setting up connections in the metadata repository, you can easily auto-generate context variables for the settings. To do so, press the Export as context button:
In the next dialog you can give it a name, then click next and you will have to option to alter the auto-generated variable list:

Now add a new query to the Metadata Repository using the SQL Builder. Make sure to tick context mode. Go to the Designer tab, right click on the text area and choose Add tables. Use the visual tool to build your query. Then switch back to the Edit tab and you will see the SQL Builder made use of the context variables.
I hope that this short introduction to context variables will help you to make your data integration jobs easier to configure!