This is the second article on clustering ETL transformations with Pentaho Kettle (Pentaho Data Integration). It is highly recommended that you read the first article Creating a clustered transformation in Pentaho Kettle before continuing with this one. Make sure that the slave and master servers are running and the cluster schema is defined - as outlined in the first article.
Prerequisites:
- Current version of PDI installed.
How to create a partitioning schema
Create a new transformation (or open an existing one). Click on the View tab on the left hand side and right click on Partition schemas. Choose New:
In our case we want to define a dynamic schema. Tick Dynamically create the schema definition and set the Number of partitions by slave server to 1:

How to assign the partition schema
Right click on the step that you want to assign the partition schema to and choose Partitioning.
You will be given following options:

For our purposes we want to choose Remainder of division. In the next dialog choose the partitioning schema you created earlier on:

Next specify which field should be used for partitioning. In our case this is the city field:

That’s it. Now partitioning will be dynamically applied to this step.
Why apply data partitioning on distributed ETL transformation?
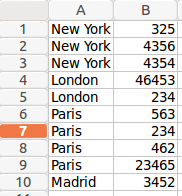
As we have 2 slave servers running (setup instructions can be find in the first article), the data will be dynamically partitioned into 2 sets based on the city field. So even if we do an aggregation on the slave servers, we will derive a clean output set on the server. To be more precise: If we don’t use partitioning in our transformation, each slave server would received data in a round robin fashion (randomly), so each data set could contain records for New York in example. Each slave creates an aggregate and when we combine the data on the master we can possibly end up we two aggregates for New York. This would then require an additional sort and aggregation step on the master to arrive at a final clean aggregate. To avoid this kind of scenario, it is best to define data partitioning, so that each slave server receives a “unique” set of data. Note, this is just one reason why you should apply partitioning.
No partitioning schema applied:


With partitioning schema applied:

Notice the difference between the two output datasets!
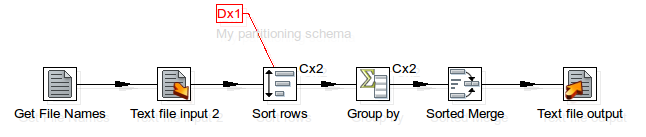
Also note the additional red icon [Dx1] in the above screenshot of the transformation. This indicates that a partitioning schema is applied to this particular step.
At the end of this second article I hope that you got a good overview of the Pentaho Kettle clustering and partitioning features which are very useful when you are dealing with a lot of data. My special thanks go to Matt and Slawo for shedding some light into this very interesting functionality.