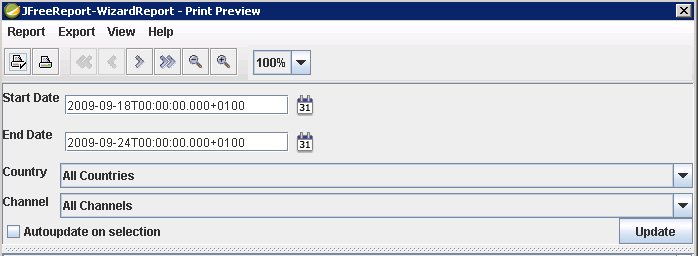
Using Parameters in Pentaho Report Designer
Introduction
You wonder what all this fuss is about? Or are you one of the many who have been struggling to use parameters in your data queries?
Using parameters with Pentaho Report Designer 3.5 (PRD) and later versions is not a trivial topic. The main problem is, that for each data source the parameter definition is different. Using parameters with standard database queries is fairly easy, using it with MDX, MQL queries and other data sources is a bit more an advance topic.
We will start off with discussing the easiest implementation and then we will move on to discuss solutions for MQL and MDX queries.
How to define a parameter
PRD 3.5 is a major improvement over previous versions of this software. One of the new features is, that you can define parameters within your report, which means, that you do not have to use Xactions any more. (You can still use Xactions for more complex logic, but generally speaking, defining the parameters within your report will make your life easier).
Within the data tab in PRD you can see a section called "Parameters". Right click on it and select "Add parameter". In the dialog you can define your parameter name, define the input type (drop down menu etc.), add a data source to populate the input dialog and make the parameter mandatory. This is all fairly straight forward and easy to set up.
Note: You have to set up the parameter before you reference it in your data queries.
Additional info about the new parameter dialog
Thomas has a very informative article on his blog about various parameter settings. I have just copied this info into here for a better overview. This section covers settings that were not available in Pentaho Report Designer 3.5, but only later releases.
::start quotation::
Hidden Parameters
By selecting a tiny little check-box, parameters can now be excluded from the UI-generation. The parameter itself still behaves like any other parameter and thus takes part in the formula-calculations and is part of the validation.
Parameter Validation can be loosened
When this flag is set to false, the validator will accept other values than the ones that have been specified in a list-parameter. With relaxed validation, you can easily write WHERE conditions, that accept partial matches or contain “LIKE” clauses. For the sake of security, we none-the-less default this feature to strict-checks.
Display-Formula
Every List-Parameter can now have computed display-texts. This way, you are no longer limited by what your data source can produce, and even a simple data-source like an XML file or a static table-datasource can produce better looking prompts.
Post-Processing Formula
A post-processing formula processes the parameter-input before it gets validated or passed into the report. The post-processing can either be defined on the parameter itself or can be defined as an extra field by using a hidden parameter. The computed value will still be validated by the engine and thus using formula’s does not necessarily mean you have to fear that illegal input comes through. Formulas allow you to access runtime information, like the current user’s roles or the user’s name via the ENV(..) function.
::end quotation::
Using parameters with database queries
From PRD 3 to PRD 3.5 the way you define your parameters in a SQL query has slightly changed.
You define a parameter within a SQL query like this: ${parametername}. Make sure you do not use enclosing single or double quotation marks, as PRD knows already how to display the parameter.
Example:
SELECT
*
FROM
table
WHERE
start_date <= ${my_start_date}
;Using parameters with Metadata/MQL queries
The easiest way to define the parameter is by using the MQL query builder. Add the data point to the filter and write {VARIABLENAME} in the value field (replace VARIABLENAME with your actual variable name; make sure it is enclosed with curly brackets). Both the parameter and the condition will then be created for you.
If you want to define your parameter in the MQL directly, use following approach:
A parameter for an MQL query can be define as follows:
Example:
<constraints>
<constraint>
<operator>AND</operator>
<condition>[TABLE.COLUMN] = [param:MY_PARAMETER]</condition>
</constraint>
</constraints>
Note: There are no enclosing brackets or a $ for the parameter_name, but the whole reference must have enclosing square brackets!
Let's have a look now at how to use date parameters in MQL. Normally, if you are using a date in MQL, you would have to use DATEVALUE("2009-11-01"), but it seems that if you are using a data parameter, DATEVALUE() shouldn't be used. As Thomas (Taqua) points out "'Normally' probably refers to 'in the old days'. But in the old days, Metadata had no parametrization at all, and all the parametrization that happened in the BI-server was a simple string-manipulation exercise on the XML code that represents the query. Thats why you in reality only passed in strings and then had to convert it via a DATEVALUE function. (And of course, its just a horrible way to do parametrization, as you now have to be careful that your strings do not break the XML or even rewrite the XML for fun and profit.)"
Define your date parameter called i.e. my_date, choose the date picker input and set the type to date.
In your MQL you reference the paramter like this:
<condition>
[Registration Time.BC_SN_LT_TIME_DIMENSION_THE_DATE] >=[param:my_date]
</condition>
Added OLAP4J (Advanced) and Mondrian (Advanced) datasources. These datasources work exactly as the SQL (Advanced) datasource by allowing the query to be computed by a formula.
Formulas can be used in parameters now. There are two formula types: Display-value computation for lists, and for all parameters a post-processor.
Parameter-Support added to OLAP4J (except for members and sets)
Using parameters with Mondrian/OLAP/MDX queries
How to pass on a single value
Imagine you want to pass on a single value to the member of a simple dimension like [Login Date].[Date]. You can use a function called parameter, which basically looks like this: parameter("parametername", dimension, member default value).
The member default value will be used (you guessed it) in case no parameter value is available. This is very useful if you are still designing your report in PRD.
Here is an example of using this approach:
SELECT
LastPeriods(6,Parameter("my_date",[Login Date],[Login Date].[2009-09-12]))
ON ROWS,
[Measures].[Distinct Users]
ON COLUMNS
from [Logins]
Since PRD 3.6 I've been also using the standard variable approach of ${variable} successfully:
WITH
MEMBER [Measures].[7daysago] AS
(CurrentDateMember([Date.Date Digits],
"[""Date.Date Digits""]\.[""Date Digits""]\.[yyyy-mm-dd]").Lag(7.0),
[Measures].[CTR])
MEMBER [Measures].[6daysago] AS
(CurrentDateMember([Date.Date Digits],
"[""Date.Date Digits""]\.[""Date Digits""]\.[yyyy-mm-dd]").Lag(6.0),
[Measures].[CTR])
MEMBER [Measures].[5daysago] AS
(CurrentDateMember([Date.Date Digits],
"[""Date.Date Digits""]\.[""Date Digits""]\.[yyyy-mm-dd]").Lag(5.0),
[Measures].[CTR])
MEMBER [Measures].[4daysago] AS
(CurrentDateMember([Date.Date Digits],
"[""Date.Date Digits""]\.[""Date Digits""]\.[yyyy-mm-dd]").Lag(4.0),
[Measures].[CTR])
MEMBER [Measures].[3daysago] AS
(CurrentDateMember([Date.Date Digits],
"[""Date.Date Digits""]\.[""Date Digits""]\.[yyyy-mm-dd]").Lag(3.0),
[Measures].[CTR])
MEMBER [Measures].[2daysago] AS
(CurrentDateMember([Date.Date Digits],
"[""Date.Date Digits""]\.[""Date Digits""]\.[yyyy-mm-dd]").Lag(2.0),
[Measures].[CTR])
MEMBER [Measures].[1daysago] AS
(CurrentDateMember([Date.Date Digits],
"[""Date.Date Digits""]\.[""Date Digits""]\.[yyyy-mm-dd]").Lag(1.0),
[Measures].[CTR])
SET [Period] AS
(CurrentDateMember([Date.Date Digits],
"[""Date.Date Digits""]\.[""Date Digits""]\.[yyyy-mm-dd]").Lag(7.0) : CurrentDateMember([Date.Date Digits],
"[""Date.Date Digits""]\.[""Date Digits""]\.[yyyy-mm-dd]").Lag(1.0))
MEMBER [Measures].[Period] AS
Avg([Period],
[Measures].[CTR])
MEMBER [Capsule].[Total Live Capsules] AS
SUM((FILTER([Capsule].[Capsule].Members,
(NOT ([Capsule].[Capsule].CurrentMember.Name MATCHES ".*test.*")))),([Measures].CurrentMember))
SELECT
{[Measures].[7daysago],
[Measures].[6daysago],
[Measures].[5daysago],
[Measures].[4daysago],
[Measures].[3daysago],
[Measures].[2daysago],
[Measures].[1daysago],
[Measures].[Period]}
ON COLUMNS,
NON EMPTY (UNION(({Filter({[Capsule].[Capsule].Members},
(NOT ([Capsule].[Capsule].CurrentMember.Name MATCHES ".*test.*")))} * {[Creative].Children}),
({[Capsule].[Total Live Capsules]} * {[Creative]}),
ALL))
ON ROWS
FROM [FUNNEL CUBE]
WHERE
({[Site].[${VAR_PARTNER_NAME}].[UNKNOWN].[${VAR_CLIENT_NAME}]} * {[Bucket Type].[TREATMENT]} * {[Ad Type].[Ad Type].[Retargeted]})How to pass on multiple values
It is very likely that you have to populate nearly the whole dimension, i.e. [Login Date.Monthly Calendar].[Monthly Calendar All].[Year].[Quarter].[Month].[Day] which would look like this: [Login Date.Monthly Calendar].[Monthly Calendar All].[2009].[Q3].[Jul].[2].
Now it gets pretty interesting: Download the latest built of PRD from here, as this will not work in PRD 3.5. The latest built includes a post-processing formula option for a parameter. Once you have the latest version installed, create a new report.
Add a parameter called my_date, choose Date Picker as type and String as format type. Now we have to write an open formula for the Post-Processing Formula entry (which is within the parameter definition dialog).
I would advise you to do this step by step, outside of the parameter definition dialog, by defining several open formula functions to extract the year, month, quarter and day part of the date and to prepare all of them separately accordingly. Drag and drop each formula function onto the report header and run your report to see if the results are correct. Once you are sure that all the results are correct, add another open formula function and concatenate all the other formula functions and additional strings that will make your final parameter. Drag and drop this final formula again on the report header and test the output.
In my case, the formula looked like this (and this must be the most impressive open formula that I have ever written):
=("[Login Date.Monthly Calendar].[Monthly Calendar All].[" & YEAR([my_date]) & "].[" & "Q" & IF(MOD(MONTH([my_date]);3 )=0; MONTH([my_date])/3; INT(MONTH([my_date])/3)+1) & "].[" & IF(MONTH([my_date])=1;"Jan";IF(MONTH([my_date])=2;"Feb";IF(MONTH([my_date])=3;"Mar";IF(MONTH([my_date])=4;"Apr";IF(MONTH([my_date])=5;"May";IF(MONTH([my_date])=6;"Jun";IF(MONTH([my_date])=7;"Jul";IF(MONTH([my_date])=8;"Aug";IF(MONTH([my_date])=9;"Sep";IF(MONTH([my_date])=10;"Oct";IF(MONTH([my_date])=11;"Nov";"Dec"))))))))))) & "].[" & DAY([my_date]) & "]")
So now that we are sure that the formula is working, we can go back to our parameter and insert this whole formula into the Post-Processing Formula field. Note: You have to pass the formula itself, and not reference the open formula function!
Now add your data source and include the parameter.
In my case, the query looks like this:
SELECT
Parameter("my_date",[Login Date.Monthly Calendar],[Login Date.Monthly Calendar].[Monthly Calendar All].[2009].[Q3].[Jul].[4]) ON ROWS,
[Measures].[Sessions] ON COLUMNS
FROM
[Logins]
That's it. I am happy that this finally works within PRD!
The below info was kindly provided by Thomas (His blog you can find here)
More info
The following info was taken from Thomas Morgner's blog:
After a million or so complaints about the complexity of building parametrized queries with the PARAMETER function within MDX, today I indulged to the demands of the crowd.
Beginning with Milestone 2 of the Pentaho Report-Designer 3.6,we now support parameter injection via the${parameter} syntax. Parameter values injected via that syntax will not be checked in any way, so it is the designer's responsibility to ensure that everything is quoted correctly to cause no harm or to break the query. With great powers comes great responsibility.
The ${parameter} syntax for MDX is not just a toString() conversion. It follows the MessageFormat syntax and thus allows to format Date and Number objects properly before inserting them into the MDX query. An extended format rule allows to produce quoted MDX-string literals by specifying the subformat <string. These strings start and end with a double-quote and all double-quote characters found in the original string get escaped according to the MDX grammar.
So now I can finally answer the question on how to parametrize a Date-Axis from a Date-parameter. To produce a member string like [2009].[10].[4] from a parameter called dateparam use[${dateparam,date,"yyyy"}].[${dateparam,date,"MM"}].[${dateparam,date,"dd"}] in your MDX query.
I still haven't found out how to do the same with the PARAMETER function.
Support for the PARAMETER function will remain there (as in theory it is a good idea to have prepared/explicit parameter).
You can test this functionality with either the latest CI build or with the upcoming Milestone 2 of the Report-Designer 3.6.
This part was originally published by Thomas Morgner on the Mondrian mailing list:
String parameters are passed into Mondrian without any postprocessing
by the reporting engine (if the parameter is a java.lang.String, otherwise we will throw a very visible exception). You are using a StrToMember which probably does not like the "{..}" syntax of the sets. Try a StrToSet instead, if you intend to pass a set.
You can also skip the parameter function and use the classical ${...} parametrization syntax (PRD 3.6 or newer), which performs a simple replacement on the MDX string. To prevent code injections you can specify a subformat along with those parameters: ${param} will include the parameter without any modification.
${param,string} will quote the parameter value as MDX string (slap double quotes around it and escape all inner double quote chars)
${param,formattype,formatstyle} will treat the parameter as a message format request, so that you can format numbers, dates and so on properly.
For the grammar of formattype and formatstyle have a look at http://download.oracle.com/doc
How to create a parameter for a set (posted by Bill W.):
WITH SET [selectedset] AS ${CSVClient}
select [selectedset] ON COLUMNS,
{[Measures].[Count of Employees], [Measures].[Count of Declined], [Measures].[Count No Record], [Measures].[Count Requested But No Vaccination Record], [Measures].[Count Vaccinated], [Measures].[Count Vaccinated Elsewhere], [Measures].[% Vaccinated], [Measures].[% Declined], [Measures].[% No Record]} ON ROWS
from [Monthly Influenza Summary]
where ([Monthly Period].[${SelectedYear}])
I am using PRD parameters to get the set of customers in a multi-select, then I turn that set into a formatted array which I use in the query. The basics are there now. XPath
- also uses the ${param} syntax to have parameters. (Same syntax as JDBC)
Reflection/Java Method Call
- parameters are given as plain names, no special encoding needed.
- parameter are separated by comma
- if the parameter-name itself contains a comma or double-quotes, quote the parameter-name by
- enclosing it in double quotes
- any inner double-quote character must be quoted by another double quote. (Parameter name : Joe"A" becomes "Joe""A""")
Pentaho Data Integration (Kettle)
You can only use a Kettle (PDI) data source in version that was released after Pentaho Report Designer 3.5.
- Parameter are declared explicitly
- PDI only accepts strings, so if the parameter is no string, then it will be converted via "toString()"
- KTR file needs to declare the parameter and arguments
Scriptable
- Scripts have a "dataRow" variable that implements org.pentaho.reporting.engine.classic.core.DataRow.
- Scripts also have access to
- "configuration" (org.pentaho.reporting.libraries.base.config.Configuration)
- "resourceBundleFactory" (org.pentaho.reporting.engine.classic.core.ResourceBundleFactory)
- "resourceManager" (org.pentaho.reporting.libraries.resourceloader.ResourceManager)
- "contextKey" (org.pentaho.reporting.libraries.resourceloader.ResourceKey)
This article would not have been possible without the help of various members in the Pentaho forum, which you can find here.
Referencing parameters in the message field
Using parameters in message fields works the following way:
Year: $(parameter)
If you want to format the parameter in a special way, you can specify the format like this:
Year: $(parameter, number, $ #,###.##)