Pentaho Data Integration: Remote execution with Carte
Tutorial Details
- Knowledge: Intermediate (To follow this tutorial you should have good knowledge of the software and hence not every single step will be described)
Carte is an often overlooked small web server that comes with Pentaho Data Integration/Kettle. It allows remote execution of transformation and jobs. It even allows you to create static and dynamic clusters, so that you can easily run your power hungry transformation or jobs on multiple servers. In this session you will get a brief introduction on how to work with Carte.
Now let's get started: SSH to the server where Kettle is running on (this assumes you have already installed Kettle there).
Encrypt password
Carte requires a user name and password. It's good practise to encrypt this password. Thankfully Kettle already comes with an encryption utility.
In the PDI/data-integration/ directory run:
sh encr.sh -carte yourpassword
OBF:1mpsdfsg323fssmmww3352gsdf7
Open pwd/kettle.pwd and copy the encrypted password after "cluster: ":
vi ./pwd/kettle.pwd
# Please note that the default password (cluster) is obfuscated using the Encr script provided in this release
# Passwords can also be entered in plain text as before
#
cluster: OBF:1mpsdfsg323fssmmww3352gsdf7
Please note that "cluster" is the default user name.
Start carte.sh
Make sure first that the port you will use is available and open.
In the simplest form you start carte with just one slave that resides on the same instance:
nohup sh carte.sh localhost 8181 > carte.err.log &
After this, press CTRL+C .
To see if it started:
tail -f carte.err.log
Although outside the scope of the session, I will give you a brief idea on how to set up a cluster: If you want to run a cluster, you have to create a configuration XML file. Examples can be found in the pwd directory. Open one of these XMLs and amend it to your needs. Then issue following command:
sh carte.sh ./pwd/carte-config-8181.xml >> ./pwd/err.log
Check if the server is running
Issue following commands:
[root@ip-11-111-11-111 data-integration]# ifconfig
eth0 Link encap:Ethernet HWaddr ...
inet addr:11.111.11.111 Bcast:
[... details omitted ...]
[root@ip-11-111-11-111 data-integration]# wget http://cluster:yourpassword@11.111.11.111:8181
--2011-01-31 13:53:02-- http://cluster:*password*@11.111.11.111:8181/
Connecting to 11.111.11.111:8181... connected.
HTTP request sent, awaiting response... 401 Unauthorized
Reusing existing connection to 11.111.11.111:8181.
HTTP request sent, awaiting response... 200 OK
Length: 158 [text/html]
Saving to: `index.html'
100%[======================================>] 158 --.-K/s in 0s
2011-01-31 13:53:02 (9.57 MB/s) - `index.html' saved [158/158]
If you get a message like the one above, a web server call is possible, hence the web server is running.
With the wget command you have to pass on the
- user name (highlighted blue)
- password (highlighted violet)
- IP address (highlighted yellow)
- port number (highlighted red)
Or you can install lynx:
[root@ip-11-111-11-111 data-integration]# yum install lynx
[root@ip-11-111-11-111 data-integration]# lynx http://cluster:yourpassword@11.111.11.111:8181
It will ask you for user name and password and then you should see a simple text representation of the website: Not more than a nearly empty Status page will be shown.
Kettle slave server
Slave server menu
Show status
Commands: Use arrow keys to move, '?' for help, 'q' to quit, '<-' to go back.
Arrow keys: Up and Down to move. Right to follow a link; Left to go back.
H)elp O)ptions P)rint G)o M)ain screen Q)uit /=search [delete]=history list
You can also just type the URL in your local web browser:
http://ec2-11-111-11-111.XXXX.compute.amazonaws.com:8181
You will be asked for user name and password and then you should see an extremely basic page.
Define salve server in Kettle
- Open Kettle, open a transformation or job
- Click on the View panel
- Right click on Slave server and select New.
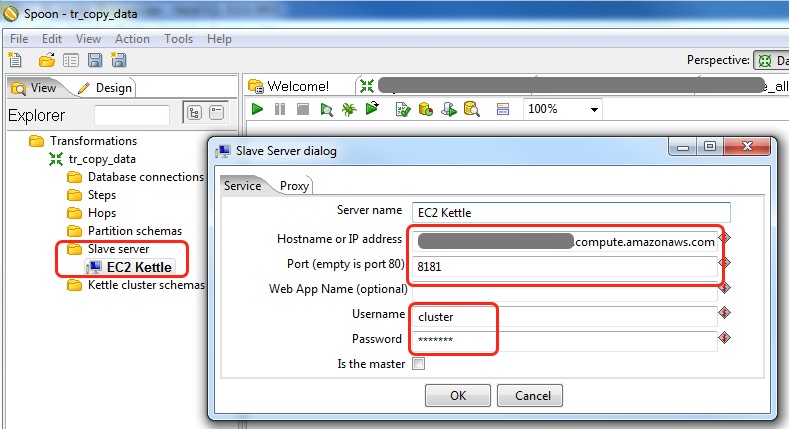
Specify all the details and click OK. In the tree view, right click on the slave server you just set up and choose Monitor. Kettle will now display the running transformations and jobs in a new tab:

Your transformations can only use the slave server if you specify it in the Execute a transformation dialog.
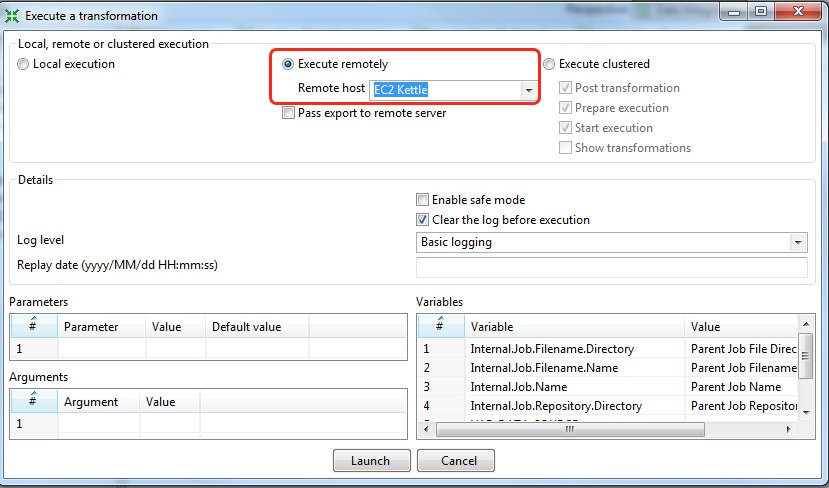
For jobs you have to specify the remote slave server in each job entry dialog.
If you want to set up a cluster schema, define the slaves first, then right click on Kettle cluster schemas. Define a Schema Name and the other details, then click on Select slave servers. Specify the servers that you want to work with and define one as the master. A full description of this process is outside the scope of this article. For further info, the "Pentaho Kettle Solutions" book will give you a detailed overview.
For me a convenient way to debug a remote execution is to open a terminal window, ssh to the remote server and tail -f carte.err.log. You can follow the error log in Spoon as well, but you'll have to refresh it manually all the time.
How to stop carte?
ReplyDeleteCurrently there doesn't seem to be a nice way to stop carte. If you are working on Unix or Linux you will have to use the kill command.
ReplyDeleteHi Diethard,
ReplyDeleteHope you are doing well. I would like to know if there is any post or documentation available regarding pentaho BI & DI installation and its best practices in an Amazon Cloud.
Typically is it similar to an installation that we will normally have in a VM? Say if we have a linux VM available we can connect through putty and install the .bin version of pentaho BI suite. From pentaho website I read something called an Amazon EC2 image is available or something. How this is different from a normal installation. Does this depend on the type of package we take from Amazon, like option for installing our own softwares or preinstalled softwares.
Many Thanks in Advance.
Sunil George.
Hi Sunil,
ReplyDeleteI am doing fine, thanks! How about you? Last time I used EC2 I just uploaded the PDI files to the server via sftp. It's just like a normal server to interact with, so you can use putty, ssh client etc. The PDI installation procedure is exactly the same: simple ... just put the files there in the right location.
I also recommend having a look at the "Pentaho Kettle Solutions" book which covers this topic as well.
Best regards,
Diethard
Hi Diethard,
ReplyDeleteI am also doing well, Thank you. Thanks a lot for your quick reply. I have that book with me, will go through it in detail. So from your inputs I assume that there won't be much challenges in having a Pentaho server in EC2. The concept will be something like we are going to have an ETL server(pentaho),a reporting server (not pentaho) and a Database Server in EC2.
Regards,
Sunil George.
Sounds like a plan! As said, it's just like setting up something on a standard server. Once you know how to connect to your EC2 instance, it's just like setting PDI on a standard server. If you haven't worked with EC2 before, setting up the EC2 instances and connecting to them will be the big learning curve ... once you familiar with this, setting up PDI is easy. Good luck!
ReplyDeleteThank you. Will keep in touch.
DeleteRegards,
Sunil
Thanks for the great tutorial. I have one burning question though.
ReplyDeleteYour tutorial is running jobs/transformation saved in the client-side.
However, is it feasible to run spoon.sh on my client computer over Carte to create jobs/transformations to be saved in the server-side repository?
I just need the spoon's GUI only for defining jobs and transformations to store in the server side's repository so that I can run them through cron on the server-side using pan.sh or kitchen.sh. I was originally thinking installing XServer on the server side so that the spoon GUI can be forwarded to my client over ssh. However, since installing XServer (particularly on Amazon AWS) is not recommended due to the heavy use of resources, I want to know if Carte can be an alternative to the scenario like mine.
Regards.
Daniel
I am not quite sure I understand your question: So you want to put the files on your server and schedule them? If you have ssh access to your server, you can just run the jobs/transformation using pan.sh or kitchen.sh (as you mentioned above). To put the files on your server, you can just use sftp. And you have cron for scheduling.
DeleteUnrelated: In Spoon, when you specify to execute the job/transformation on the server (carte), you can also specify that it should execute the file there (as opposed to your client), in which case it will copy the file across. But this is mainly useful for testing.
To make it simple,
DeleteI have been using ssh to the server with -X option (e.g. ssh -X user@hostname) from my client. And run the spoon.sh from the command line, which forwards the Spoon GUI to my client. I then execute or create jobs/transformations, which will run or save the jobs/transformations on the server side.
I there an equivalent way of doing it through Carte? That is, can my Spoon on my client directly execute or create jobs/transformations on the server side?
Hopefully, this makes more sense to you.
Thanks again.
Daniel
Ok, I see. Not really ... not that I am aware of at least. I usually develop and test locally (or test server) and only then make the transformations/jobs available on the prod server.
DeleteThanks, Diethard. I think your framework would still be a better option than running though XServer.
DeleteA good Git setup will help you here.. If you have a repo on, say, GitHub or Bitbucket, with all your jobs / transformations, that's cloned on the production server, you can do development work locally, and push it to the main repo when you're done. Then you go to the production server and just do a pull to get all the latest changes.
DeleteFor a more advanced setup, dedicate a branch to production code, eg. "prod". Then do your development on the regular "master" branch and push all you like to GitHub / Bitbucket without worrying about messing with the production server. Once you're ready to release, you merge the changes on master to the "prod" branch, and then do a pull on the server.
Taking it one step further, you can have a script running every 5 mins or so in crontab on the server, that will automatically pull any changes to "prod" down to the server. Now you've got automatic deployment -- but make sure you've tested your changes properly!
With all this, it's of course important to have all parameters like database connections etc parameterized, probably using a KETTLE_HOME that's actually inside the Git repo, that's different for prod and dev, and with your parameters in .kettle/kettle.properties so they get automatically loaded. Then you just use wrapper scripts around kitchen.sh and pan.sh to run your jobs / transformations on the server, that set KETTLE_HOME to the prod version. If running locally, you can have different wrapper scripts, or set it manually, for example.
You're probably already doing many of these things, so sorry if I'm rambling.. I hope you find something useful here though :)
Hi Johan, Thanks a lot for your feedback. Yes indeed, I have my project set up in a similar fashion. Maybe at some point I'll write a blog post about general project setup to discuss this topic a bit in more detail.
DeleteHi Diethard,
ReplyDeleteGreat blog, I always enjoy reading the articles about PDI when looking for some tipps and tricks :)
Regarding this post: is there also a way to send a job to an already running Carte server via command line?
Thanks for any hint!
Max
Thanks for your feedback Max! Not that I am aware of, but you could just use the sftp command instead to put the file onto the remote server and then you can just call the job as a web service (see my recent blog post) or start it via the carte web interface.
DeleteHi .. Great blog!!
ReplyDeleteI am facing with one issue : How to get the new job entry's into carte web server's ?
Is their any way to make the entry's dynamic ??