If you are working in a project which involves properly set up development, testing and production environments, database version control should be mandatory. The good news is that there are actually some open source tools out there which can help you with that. The bad news is, that none of them can be considered in active development and none of them probably found the recognition and widespread usage that their original developers set out for.
About a year ago I tried to find some open source projects for database version control, the two tools I could find at that time were dbmaintain and neXtep. Judging by their release history one might think that these projects are dormant. So I kind of gave up on this topic. This year then at the Pentaho User Meeting in Amsterdam Edwin Weber actually mentioned neXtep in his presentation and I had a brief conversation with him afterwards about his experience with this particular tool. He mentioned that although there were no new releases, there were still patches submitted for that tool. So I kind of thought, let’s give this a try. I finally came around to take a look at neXtep just a week ago.
After registering you can download the neXtep Studio, which is Eclipse based. Setting it up is fairly straightforward and the interface is fairly intuitive as well. What I was not expecting is that the documentation was that good. It seems like the people behind this project spent really a considerable amount of time in creating what I would call an excellent documentation, which you can find here.
There is also a forum where I even got some answers to my questions! If someone fancies adding support for additional databases, some documentation can be found here and here.
The aim of this post is not to walk you through the tool, as their Wiki really is the best place to find that insight, it is just a way of saying: “Hey, there is this impressive tool out there for database version control, start using it and give them some support!”.
I think, that, although it is very often neglected, database version control is a very important topic. Version your database sooner than later!
Some notes on the installation:
I had some problems with setting up the neXtep repository on
- PostgreSQL 9.2: Two columns could not be created. See here on how to solve this problem.
- MySQL 5.5: The installer started hanging when performing the final upgrade of the repository. I just killed the process and started neXtep Studio again after which it successfully upgraded the repository. I couldn’t create any user then, but luckily (in this case) the password is stored as plain text in the db table. Run:
SELECT * FROM nextep_repo.REP_USERS;
How to use neXtep’s database version control
This is an extremely simplified setup: Let’s imagine we already have one table in our PostgreSQL database (users with MySQL, MS SQL or Oracle databases please adjust the SQL respectively):CREATE DATABASE nextep;
\connect nextep
CREATE SCHEMA test;
CREATE TABLE
test.user
(
firstname VARCHAR(50)
, lastname VARCHAR(50)
)
;
We decide to start with database version control, because things are going to get much more complex pretty soon once the project starts rolling.
On the terminal (in my case on Ubuntu) navigate to the neXtep install directory and start the Studio (this takes into account that you have already set up the neXtep repository and users):
./neXtep
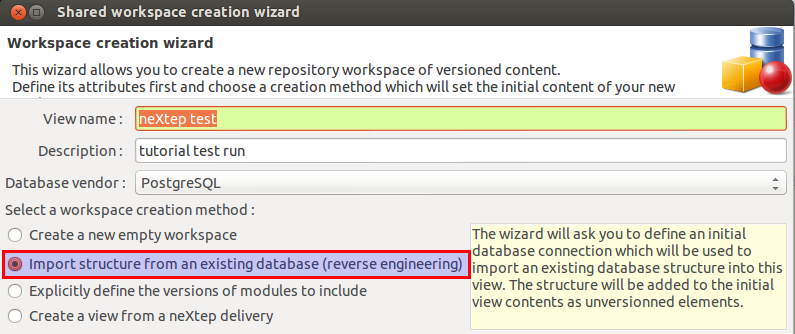
When the Shared Workspace selection dialog comes up, choose New Workspace. Then provide a name, description and select PostgreSQL as database vendor. Make sure you then select Import structure from an existing database (reverse engineering):
Now provide all the database connection details and test the connection:
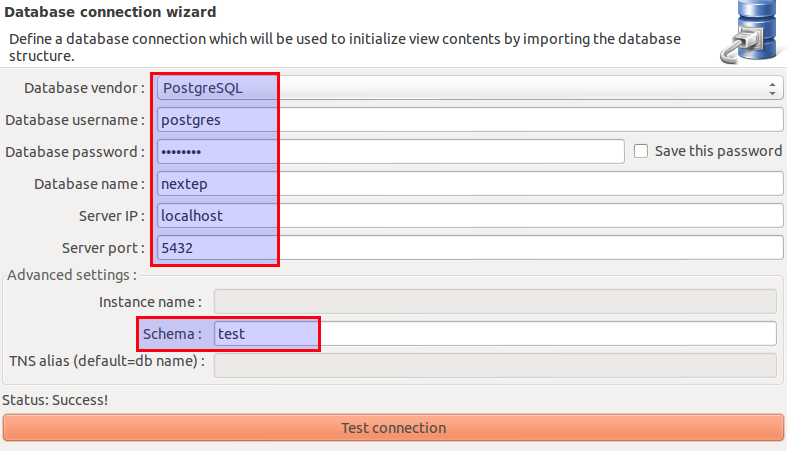
Click Next. You will be asked to for the DB password again (make sure you tick to save it this time).
Now pay special attention to the Version Navigator on the left hand side of the Studio:

Right click on the module, the second element in the hierarchy, Nextep Test, and choose commit:
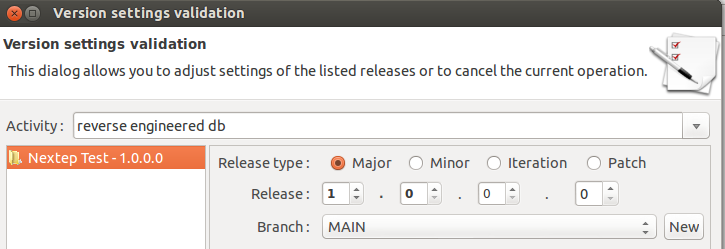
In this case we will not change the version number (but we will do so in future). Add a good description and then click commit. Now you will see that module as well as the table name have a lock symbol attached.
Next mark the table name and click on the Check Out button (or alternatively right click on the table name and choose Check Out):

A new dialog comes up, called Problem Solver Wizard, just click Finish. Next provide a good description of the changes you are about to make. You will see that neXtep automatically increase the patch number, which is just what we want in this case. We also want to work on the main branch:
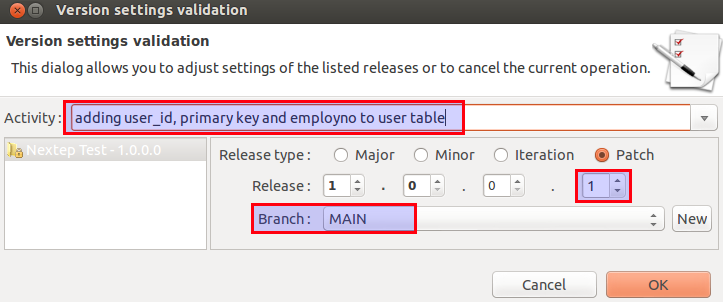
Click Ok.
Notice that the lock symbols disappeared in the Version Navigator and that the version number increased.
In the Version Navigator double click on the user table. You will now see a new Table Overview coming up. Let’s now add a new column called user_id. Click on the Columns tab at the bottom of the Table Overview, then click on Add:
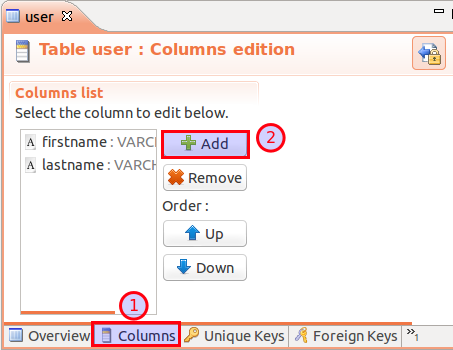
Add following columns:
- userid: SERIAL
- employeeno: VARCHAR(20); description: alpanumeric code
Click on the Primary Keys tab and a new primary key called PK_userid and assign the userid column:

We also want to pay attention on the error message neXtep brought up: We forgot to define the userid column as NOT NULL, so we go right back to the Columns tab and change the userid accordingly:
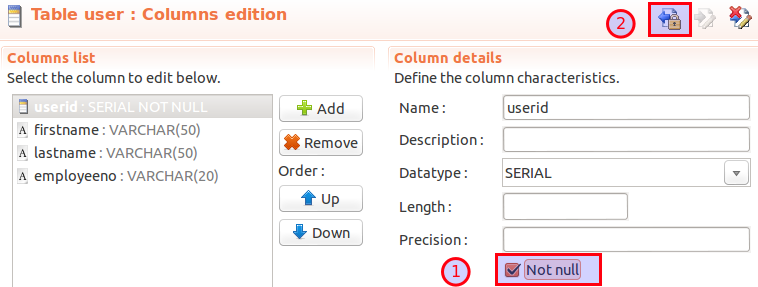
As we have implemented all the required changes, we are ready to commit them. Click on the Commit and lock this version button. You have now one more time the chance to adjust the description, then click commit.
Note that the version number increased again:
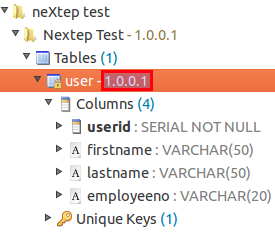
Then click on the Synchronize DB button:

This opens the Synchronization perspective.
The Synchronization pane gives you an exact overview of the changed since the last applied version:
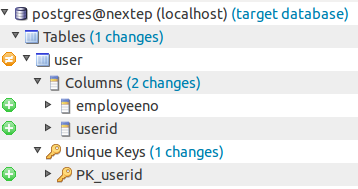
It highlights that we added the employeeno and userid columns as well as a primary key called PK_userid.
In the main work area you can see the DDL neXtep generated to upgrade our target database from version 1.0.0.0 to 1.0.0.1:
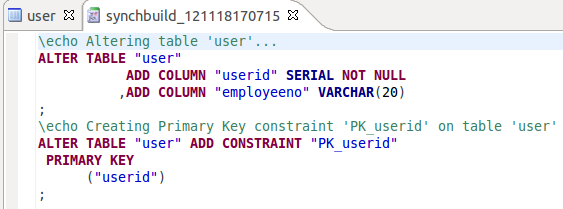
As this looks all quite fine for us, we click on the Execute button:

And all these changes will be applied to our target database. Watch the Console view for any progress messages.
It’s always good practice to click the Synchronize button again just to make sure that our model matches the DB model. As we can see in our case, something is not quite alright:

What basically happened is that PostgreSQL created its own sequence for the userid and also changed the data type to Integer. This is fine for us, so we can just incorporate these changes. Click on the Repository reverse synchronization from database information button and then click Execute:

Now we want to ensure that everything is properly in sync again, so we click the Synchronize database button again. Now everything is fine (click the Shows/Hides unchanged items button as well):
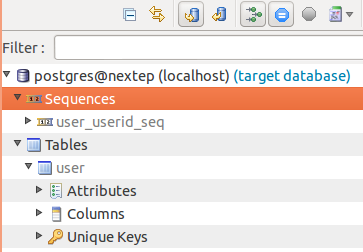
Go back to the Database Design perspective and have a look if the changes were applied. We can see that a new sequence was added (in the Version Navigator)

and that the userid column details changed:
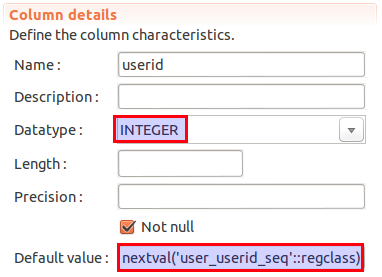
To be fair, we could have set it up like this in the first place, but now at least you got a bit more exposed to the synchronization options.
How to create a branch
This is now our first release, which will be delivered to the test environment. Let’s create a new branch test to commit these changes there:Click on the module Nextep Test and choose Commit. Provide an activity description and click on Iteration. Then click on new and create a Test branch:

Click Next followed by Finish.
Note that the version tree gets automatically updated:
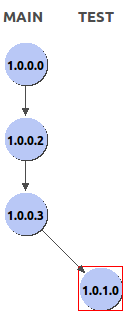
We could now package and deliver this model (available via a right click action on the module name). neXtep also supplies a command line tool called neXtep Installer (more info here) which is able to deploy database deliveries generated by the neXtep Studio.
How to merge
Obviously we also want to have all these improvements in the main branch, so we can use the merge action. First we have to go back to the last version of the MAIN trunk. We do this by creating a new workspace.Choose Workspace > Create new workspace and make sure you select the Explicitly define the versions of the modules option.
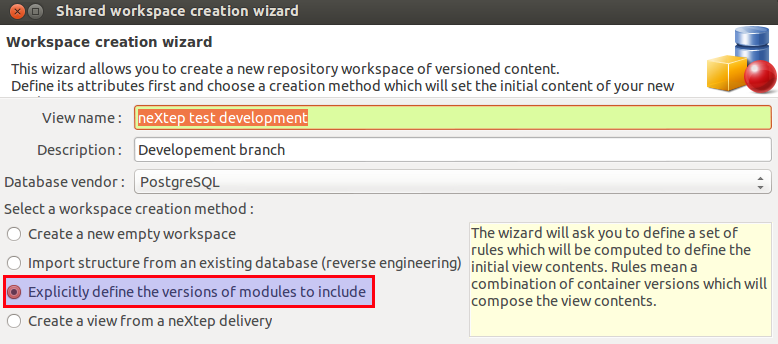
In the View rules definition wizard choose the latest version of the main trunk and click Add module to view:
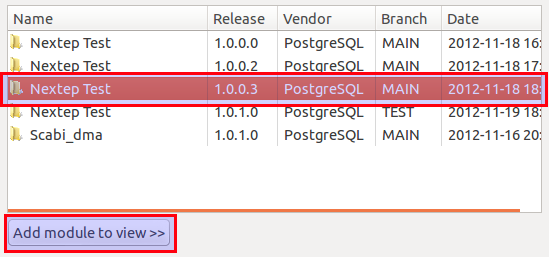
Click Finish.
As you can see in the Version Navigator our new workspace is based on the latest main trunk version:
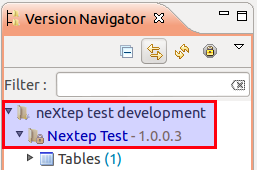
If you now click on Workspace > Change Workspace you will see that you can now switch between the main and test trunk versions by switching between these two workspaces (ok, we should have named it in a better fashion):

Workspace: Versions are not bound to a particular workspace. A workspace is just a space where you define the set of elements you need to work on, and you can create as many workspaces as you need. [source: neXtep site]
Click on Cancel.
Now we want to merge the latest version of the Test branch with this one, so that we have all the changes over here for a good base to add future developments:
Right click on the module Nextep Test and choose Merge to ..., which brings up the Merge Wizard. Click on the latest version of the Test branch in the diagram:
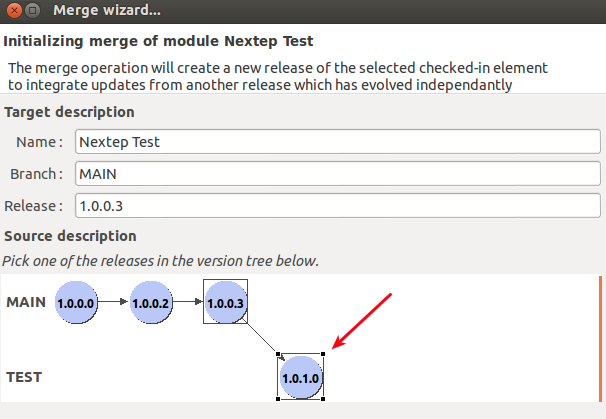
Click Next and you will see a graphical representation of the changes you requested:
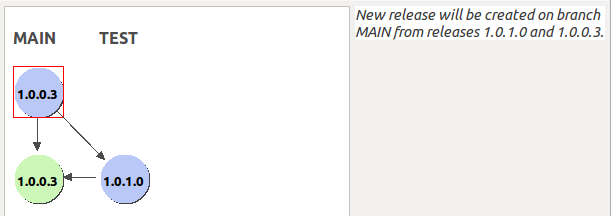
Now you will see a detailed overview of the merge results (note that the screenshot might not 100% match with yours because I added a few other things, but you get the idea):

Click Ok.