Pentaho Data Integration (Kettle): Command line arguments and scheduling
Tutorial Details
- Knowledge: Intermediate (To follow this tutorial you should have good knowledge of the software and hence not every single step will be described)
- OS: Linux or Mac OS X
- Tutorial files can be downloaded here
Once you tested your transformations and jobs there comes the time when you have to schedule them. You want to have a certain amount of flexibility when executing your Pentaho Data Integration/Kettle jobs and transformations. This is where command line arguments come in quite handy.
A quite common example is to provide the start and end date for a SQL query that imports the raw data. Kettle makes it very easy actually to set this up.
Approach to provide arguments to one step in a transformation
If you just need the arguments for one step only, then you can use the Get System Info step and create a hop to your Database Input step.
We will be working with following data set:
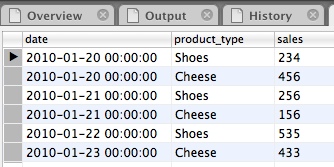
Open your favourite SQL Client (and start your MySQL server if it is not running yet) and issue following SQL statements:
USE
test
;
DROP TABLE IF EXISTS
`sales`
;
CREATE TABLE
`sales`
(
`date` DATETIME,
`product_type` VARCHAR(45),
`sales` INT(255)
)
;
INSERT INTO
`sales`
VALUES
('2010-01-20 00:00:00','Shoes',234),
('2010-01-20 00:00:00','Cheese',456),
('2010-01-21 00:00:00','Shoes',256),
('2010-01-21 00:00:00','Cheese',156),
('2010-01-22 00:00:00','Shoes',535),
('2010-01-23 00:00:00','Cheese',433)
;
SELECT
*
FROM
`sales`
;
CREATE TABLE
`sales_staging`
(
`date` DATETIME,
`product_type` VARCHAR(45),
`sales` INT(255)
)
;
Our goal is to provide the start and end date arguments to our SQL query.
Now let's create our transformation:
- Open Kettle and create a new transformation
- Drag and drop a Get System Info step on the canvas. You can find it in the Input folder on the left hand side.
- Double click on it and populate the names column in the grid with start_date and end_date.
- For the type choose command line argument 1 and command line argument 2 respectively

Now add a Table input step and a Table output step (we keep it very simple). Create hops between all these steps in the order that they were mentioned.
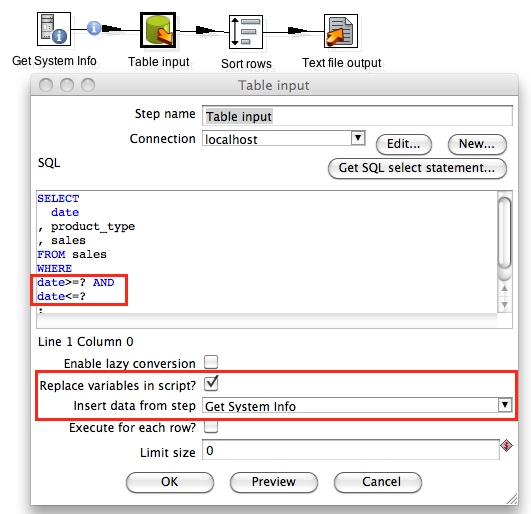
Double Click on the Table Input step and populate the SQL field with the query shown below:
SELECT
date
, product_type
, sales
FROM sales
WHERE
date>=? AND
date<?
;
You can feed the start and end date from the Get System Info step to a Table Input step and use the start and end date in the WHERE clause of your SQL query (highlighted in yellow). The question marks will be replaced on execution by the start and end date (but make sure they are defined in this order in the Get System Info step).
Make sure that you enable Replace variables in script? and choose the Get System Info step for Insert data from step.
Define a New ... connection (Connection Name: Localhost, Connection Type: MySQL, Host Name: localhost, Database Name: test, Port Number: 3306, your user name and password).
Click OK. The hop between the Get System Info step and the Table Input step now also displays an info icon.
And this is all that you have to do: Your transformation now accepts command line arguments!
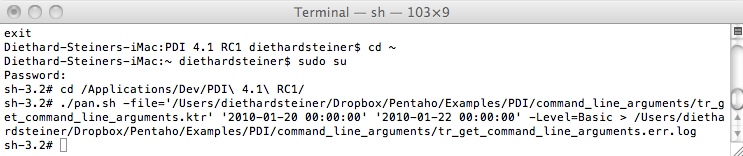
So now let's try to execute the transformation from the command line. Close all the files that we just created, then open your Terminal window.
My transformation is located in:
/Users/diethardsteiner/Dropbox/Pentaho/Examples/PDI/command_line_arguments/tr_get_command_line_arguments.ktr
To execute a transformation from the command line, we have to call pan.sh, which is located in my case in:
/Applications/Dev/PDI\ 4.1\ RC1/pan.sh
Use following approach to execute the transformation (replace the file paths by yours):
Change to the PDI directory:
cd /Applications/Dev/PDI\ 4.1\ RC1/
Use the super user and provide the password:
sudo su
Issue following command (replace yellow highlighted paths with your paths):
./pan.sh -file='/Users/diethardsteiner/Dropbox/Pentaho/Examples/PDI/command_line_arguments/tr_get_command_line_arguments.ktr' '2010-01-20 00:00:00' '2010-01-22 00:00:00' -Level=Basic > /Users/diethardsteiner/Dropbox/Pentaho/Examples/PDI/command_line_arguments/tr_get_command_line_arguments.err.log
Command line parameters (highlighted in red) have to be mentioned after the file argument. Mention them in the order that you expect them to be received in Kettle. The level argument (highlighted in blue) specifies the logging level. Following levels are available (from the most detailed one to the least detailed one): Rowlevel, Detailed, Debug, Basic, Minimal, Error, Nothing.
Pan accepts many more arguments, i.e. to connect to the repository. Please have a look at the Pan User Documentation for all the details.
Once the command is issued and you get no error message returned (check the error file), let's check the data that got exported to our output table:

As you can see from the screenshot above, only the data covering our specified timeframe got processed.
Approach to provide arguments to more transformations and jobs
If you plan to use the command line arguments in more than one step and/or more transformations, the important point is that you will have to do this in a separate transformation which has to be executed before the transformation(s) that require(s) these variables. Let’s call this transformation Set Variables.
The Set Variables transformation has two steps:
- Get System Info: It allows you to define variables that are expected to come from the command line
- Set Variables: This one will then set the variables for the execution within Kettle, so that you can use them in the next transformation that is specified in your job.
Note: The command line arguments enter Kettle as a String. In some cases the variable is expected to be of a certain data type. Then you will have to use the Get Variable step in a succeeding transformation to define the specific data type for each variable.
|
There is no additional adjustment needed. Do not fill out the Parameters tab in the Transformation properties or Job properties with these variables!
We can now change our main transformation to make use of these variables.
A typical scenario would be the following: Our ETL process populates a data warehouse (DWH). Before we insert the compiled data into the DWH, we want to make sure that the same data doesn't already exist in it. Hence we decide, that we just want to execute a delete statement that clears the way before we add the newly compiled data.
Our ETL job will do this:
- Initialise the variables that are used through the job (done in a dedicated transformation)
- Delete any existing DWH entries for the same time period (done in a SQL job entry)
- Main ETL transformation
Let's start:
- Create a new transformation and call it tr_set_variables.ktr
- Drag and drop a Get System Info step on the canvas. You can find it in the Input folder on the left hand side.
- Double click on it and populate the names column in the grid with start_date and end_date.
- For the type choose command line argument 1 and command line argument 2 respectively
- Next drag and drop the Set Variables step from the Job Folder onto the canvas and create a hop from the Get System Info step to this one.
- Double click the Set Variables step and click on Get Fields:
Clicking Get Fields will automatically define all input fields as variables. If you don't need all, just delete the relevant rows. In our case we want to keep all of them. Kettle will also automatically capitalize the variable names. As I want to avoid any confusion later on, I explicitly prefix my variables in Kettle with VAR_. You can also define scope type and set a default value.
We have now create a transformation that accepts command line arguments and sets them as variables for the whole job.
Next, let's create the main ETL transformation:
- Open tr_get_command_line_arguments (which we created earlier on) and save it as tr_populate_staging_tables.
- Delete the Get System Info step. We don't need this step any more as we define the variables already in tr_set_variables.
- Double click the Table input step. As our variable can be referenced by names, we have to replace the question marks (?) with our variable names like this:
SELECT
date
, product_type
, sales
FROM sales
WHERE
date>="${VAR_START_DATE}" AND
date<"${VAR_END_DATE}"
;
The variables are now enclosed by quotation marks as we want the date to be treated as string. - Click Ok and save the transformation.
- Create a new job and name it jb_populate_staging_tables.
- Insert following job entries in the order specified and connect them with hops:
- Start entry
- Tranformation entry: Double click on it and choose tr_set_variables.ktr as the Transformation filename.
- From the Script Folder choose the Execute SQL script ... job entry: Define a New ... connection (Connection Name: Localhost, Connection Type: MySQL, Host Name: localhost, Database Name: test, Port Number: 3306, your user name and password). Tick Use variable substitution?. Insert following query:
DELETE FROM
sales_staging
WHERE
date>="${VAR_START_DATE}" AND
date<"${VAR_END_DATE}"
;
Pay attention to the where clause: The variables are now enclosed by quotation marks as we want the date to be treated as string. Also note that the date restriction is exactly the same as the one we use for the raw data import. - Transformation entry: Double click on it and choose tr_populate_staging_tables.ktr as the Transformation filename.

So now let's try to execute the transformation from the command line. Close all the files that we just created, then open your Terminal window.
My job is located in:
/Users/diethardsteiner/Dropbox/Pentaho/Examples/PDI/command_line_arguments/jb_populate_staging_tables.kjb
To execute a job from the command line, we have to call kitchen.sh, which is located in my case in:
/Applications/Dev/PDI\ 4.1\ RC1/pan.sh
Use following approach to execute the transformation (replace the file paths by yours):
Change to the PDI directory:
cd /Applications/Dev/PDI\ 4.1\ RC1/
Use the super user and provide the password:
sudo su
Issue following command (replace yellow highlighted paths with your paths):
./kitchen.sh -file='/Users/diethardsteiner/Dropbox/Pentaho/Examples/PDI/command_line_arguments/jb_populate_staging_tables.kjb' '2010-01-20 00:00:00' '2010-01-22 00:00:00' -Level=Basic > /Users/diethardsteiner/Dropbox/Pentaho/Examples/PDI/command_line_arguments/jb_populate_staging_tables.err.log
Command line parameters (highlighted in red) have to be mentioned after the file argument. Mention them in the order that you expect them to be received in Kettle. The level argument (highlighted in blue) specifies the logging level. Following levels are available (from the most detailed one to the least detailed one): Rowlevel, Detailed, Debug, Basic, Minimal, Error, Nothing.
Kitchen accepts many more arguments, i.e. to connect to the repository. Please have a look at the Kitchen User Documentation for all the details.
Inspect the error log to see if the job ran successfully. Then have a look at the staging table to see if the data got imported.
Using named Parameters
Named parameters are special in the sense that they are explicitly named command line arguments. If you pass on a lot of arguments to your Kettle job or transformation, it might help to assign those values to an explicitly named parameter.
Named Parameters have following advantages:
- On the command line you assign the value directly to a parameter, hence there is zero chance of a mix-up.
- A default value can be defined for a named parameter
- A description can be provided for a named parameter
- No need for an additional transformation that sets the variables for the job
Let's reuse the job that we created in the previous example:
- Open jb_populate_staging_tables.kjb and save it as tr_populate_staging_tables_using_named_params.kjb.
- Delete the Set Variables job entry and create a hub from the Start to the Execute SQL script entry.
- Click CTRL+J to call the Job properties dialog.
- Click on the Parameters tab and specify the parameters like this:
In our case we don't define a default value. The reason for this is that we don't want to import any raw data in case there is no start and end date defined.
- Click Ok and save the job.
Our job is completely set up. Let's execute it on the command line:
./kitchen.sh -file='/Users/diethardsteiner/Dropbox/Pentaho/Examples/PDI/command_line_arguments/jb_populate_staging_tables_using_named_params.kjb' -param:VAR_START_DATE='2010-01-20 00:00:00' -param:VAR_END_DATE='2010-01-22 00:00:00' -Level=Basic > /Users/diethardsteiner/Dropbox/Pentaho/Examples/PDI/command_line_arguments/jb_populate_staging_tables_using_named_params.err.log
I described the various kitchen arguments in the previous section, so I won't repeat it here. The only difference here are the named parameters (highlighted in yellow).
Inspect the error log to see if the job ran successfully. Then have a look at the staging table to see if the data got imported.
As you can see, named parameters are the crème de la crème!
Scheduling a job on Linux
Now that we have quite intensively explored the possibilites of passing command line arguments to Kettle, it's time to have a look at scheduling:
On Linux crontab is a popular utility that allows to schedule processes. I will not explain crontab here, if you are new to it and want to find out more about it, have a look here.
Our plan is to schedule a job to run every day at 23:00. We pass on two command line arguments to this job: the start and the end datetime. It's required that this job imports each time the raw data of the last two days (23:00 to 23:00). To calculate the start and end date for the raw data processing we will write a shell script. The plan is to schedule this shell script using crontab.
You can edit the crontab by issuing following command:
crontab -e
This will display any scheduled processes. If you are familiar with vi, you can use the same commands here to edit and save. Click i to insert the following:
00 23 * * * /jb_populate_staging_tables_daily.sh
Press ESC followed by :wq to save and exit crontab.
Navigate to the folder where you saved all the jobs and transformations. Create this shell script with vi and name it jb_populate_staging_tables_daily.sh:
cd /Applications/Dev/PDI\ 4.1\ RC1;./kitchen.sh -file='/Users/diethardsteiner/Dropbox/Pentaho/Examples/PDI/command_line_arguments/jb_populate_staging_tables.kjb' "`date --date='2 days ago' '+%Y-%m-%d 23:00:00'`" "`date --date='1 day ago' '+%Y-%m-%d 23:00:00'`" -Level=Basic > populate_staging_tables_daily.err.log
Note: We enclosed our arguments with double quotes. We used enclosing back ticks to indicate that a shell command has to be executed. There is also a blank in our argument, which we enclosed by using single quotes (otherwise Linux is expecting another argument).
|
Our job is now scheduled. Make sure that you check after the first run for any errors.
In this article you learnt about creating flexible jobs and transformations by using command line arguments. We also had a quick look at scheduling your jobs. I hope this article demonstrated that it is quite easy to set this up.
Thanks for the info. I have been using Kettle for almost 2 years. I have had sporadic luck with the process above. I use Ubuntu 10.10 server, using MAC OS X Snow Leopard, Kettle version 4.1.
ReplyDeleteI have defined the job parameter as described above and use the command line to pass the parameter. I get:
Unknown column '$' in 'where clause'
org.pentaho.di.core.database.Database.openQuery(Database.java:1869)
org.pentaho.di.trans.steps.tableinput.TableInput.doQuery(TableInput.java:221)
org.pentaho.di.trans.steps.tableinput.TableInput.processRow(TableInput.java:130)
org.pentaho.di.trans.step.RunThread.run(RunThread.java:40)
java.lang.Thread.run(Thread.java:619)
The exact job works just fine with Ubuntu 9.04.
Any help would be appreciated greatly.
Mark
Can you post your query? Plus, please also post what you write on the command line. Then it's easier to provide feedback ...
ReplyDeleteI set the variables using a transformation with a Set Variables step.
ReplyDeleteThe Sql I am using:
****
SELECT
concat(a.name,"-",year(now())) as campaign_name
, a.campaign_fromname
, a.campaign_fromnaddress
, a.campaign_replytoname
, a.campaign_replytoaddress
, a.inbound_email_id
, a.campaign_freq
, a.campaign_domain
, a.description as targetlist_sql
,a.campaign_type
,a.active
,a.jobid
,b.id as temp_id
,concat(a.name,"-",year(now()),"- List") as list_name
,concat(a.name,"-",year(now()),"- UnSubscription List") as unsub_list_name
FROM cf_email_campaign_factory a
JOIN email_templates b
WHERE
a.jobid="${JOBID}"
and
a.active=1
and b.name like concat(a.email_tempname,'%')
****
Then I run the job by:
./kitchen.sh -rep ETL_MKT -user admin -pass admin -job Create_Campaign_WithCoupon -param:JOBID='6'
And I get:
INFO 07-04 18:24:50,805 - Using "/tmp/vfs_cache" as temporary files store.
INFO 07-04 18:24:52,250 - Kitchen - Start of run.
INFO 07-04 18:24:52,308 - RepositoriesMeta - Reading repositories XML file: /opt/data-integration/.kettle/repositories.xml
INFO 07-04 18:24:53,632 - Create_Campaign_WithCoupon - Start of job execution
INFO 07-04 18:24:53,635 - Create_Campaign_WithCoupon - Starting entry [Set_Campaign_Variables]
INFO 07-04 18:24:53,636 - Set_Campaign_Variables - Loading transformation from repository [Set_Campaign_Variables] in directory [/]
INFO 07-04 18:24:54,260 - Set_Campaign_Variables - Dispatching started for transformation [Set_Campaign_Variables]
INFO 07-04 18:24:54,325 - Set_Campaign_Variables - This transformation can be replayed with replay date: 2011/04/07 18:24:54
INFO 07-04 18:24:54,376 - FROM cf_campaign_factory - Finished reading query, closing connection.
INFO 07-04 18:24:54,383 - Set Variables - We didn't receive a row while setting the default values.
INFO 07-04 18:24:54,383 - Set Variables - Finished after 0 rows.
INFO 07-04 18:24:54,385 - Create_Campaign_WithCoupon - Finished job entry [Set_Campaign_Variables] (result=[true])
INFO 07-04 18:24:54,385 - Create_Campaign_WithCoupon - Job execution finished
INFO 07-04 18:24:54,388 - Kitchen - Finished!
INFO 07-04 18:24:54,388 - Kitchen - Start=2011/04/07 18:24:52.251, Stop=2011/04/07 18:24:54.388
INFO 07-04 18:24:54,389 - Kitchen - Processing ended after 2 seconds.
So it does not pick up the parameter passed by the job. if I assign it manually the it sets the variables.
Thanks in advance.
Mark
Hi Mark,
ReplyDeleteIt is a bit difficult to answer this as I don't know how you set up your job and/or transformations. Did you enable "Replace variables in script" in the Table Input step? Also, did you define the variables in the job settings as shown in the tutorial?
Best regards,
Diethard
The funny thing is the whole stepup works from the gui. It sets the variable and everything. I suspect there might be some bug in Kitchen - Kettle version 4.1.1, build 14732, build date : 2011-01-21 06.24.57
ReplyDelete..
Is your job similar to the one described in "Using named Parameters" in my tutorial? If yes, you don't need the set variables step. Another advice is to start really simple. Is this your first time you try to pass named parameters to Kettle? If yes, just try it with a simple transformation that does nothing else but outputting the supplied variables to a text file. If this works, gradually make it more complex.
ReplyDeleteHi Diethard,
ReplyDeleteYes, I put the parameter in Job settings. I can see and set the parameter when I wanted to execute it from the gui. I think I hit a bug since -listparam from the command line does not show anything. I will install the trunk from SVN and see if I get any luck.
Regards,
Mark
Hi Diethard,
ReplyDeleteNeed to be careful when using quotes in MySQL. Your code will fail if the SQL_MODE session variable is set to ANSI (or just ANSI_QUOTES) since double-quotes are then used to enclose identifiers rather than literal values. Using single quotes is a much safer way to go.
This may or may not be related to the problem above. Both your code and mark's use double instead of single.
Cheers,
Paul
Thanks Paul for pointing this out!
ReplyDeleteHi Paul,
ReplyDeleteI installed the trunk version:
./kitchen.sh -rep ETL_MKT -user admin -pass admin -version
INFO 08-04 17:46:11,954 - Using "/tmp/vfs_cache" as temporary files store.
INFO 08-04 17:46:14,529 - Kitchen - Kettle version 4.2.0-M1, build 14991, build date : 2011-04-07 06.21.19
INFO 08-04 17:46:14,529 - Kitchen - Start of run.
INFO 08-04 17:46:14,610 - RepositoriesMeta - Reading repositories XML file: /opt/data-integration/.kettle/repositories.xml
****
it still returns:
./kitchen.sh -rep ETL_MKT -user admin -pass admin -job Create_Campaign_WithCoupon -listparam
INFO 08-04 17:45:22,723 - Using "/tmp/vfs_cache" as temporary files store.
INFO 08-04 17:45:25,309 - Kitchen - Start of run.
INFO 08-04 17:45:25,387 - RepositoriesMeta - Reading repositories XML file: /opt/data-integration/.kettle/repositories.xml
****
No parameter for the job. I changed the parameter assignment to single quotes. No luck. Gui (os x snow leopard)works as it should.
I am running everything on Mac OS X Snow Leopard as well and it is working fine with PDI 4.1. I am not too sure why you use quotation marks for the jobid variable in your SQL ... I assume jobid is not a string but an integer, so you don't need quotation marks at all. Can you upload your files somewhere (dropbox, google docs or similar) then I might have a chance to look at them this weekend (no promises, if I find time).
ReplyDeleteHi Diethard,
ReplyDeleteMy issue is not structure of the job or transformation. The Kettle gui does not save job parameters in the repository. That's why -listparam returns nothing in the command line. While gui caches the param hence running without an issue. it might be a bug, I do not know.
Thanks.
In the mean time that particular bug was fixed just over a week ago on April 1st : http://jira.pentaho.com/browse/PDI-5384
ReplyDeleteGreat news! Thanks a lot Matt for letting us know!
ReplyDeleteWhat about running into Windows XP? I have tried with this:
ReplyDeletePan.bat /file:"C:\MappingRiesgos\Scripts\CasiopeaUniverso.ktr" /level:Basic
Even thought, I did some modifications within the comman, such as = instead of : or - instead of /.
I'd really appreciate your help.
Thanks in advance!!
Pan.bat /file:cli_test_parameters.ktr 200 500
Deletewill work for windows. If you have spaces in your parameter, use underscore in the place of that, like;
Pan.bat /file:cli_test_parameters.ktr 2010-01-20_00:00:00 2010-01-22_00:00:00
On Windows, it looks something like this:
ReplyDeletecall C:\Pentaho\pdi-ce-4.2.0-M1-r14968\kitchen.bat /file:C:\Pentaho\my-files\bi_v1.1\reports\daily_performance_report\jb_performance_report_master.kjb /level:Basic "-param:VAR_DATA_SOURCE=infinidb_dwh" "-param:VAR_REPORT_NAME=DAILY PERFORMANCE REPORTS" > C:\Pentaho\my-files\bi_v1.1\reports\daily_performance_report\err2.log
Hello
ReplyDeleteIs it possible to have Named Parameters for DB Connections, saved in Repository ? OR to change the data automatically in kettle.properties automatically depending on repository?
In all my 5 repositories (TEST, PROD, DEV...) I use the same Named Parameters (${DB.HOST}...), but I have different values for them cause I connect to different DBs, Servers.
I encounter recently a problem with Named Parameters when I am switching between repositories, because the values of Named Parameters remain unchanged in kettle.properties.
So if in kettle.properties I have the configuration for TEST rep, and I load PROD rep then the Named Parameters will still point towards the TEST rep cause the values where not changed.
NOTE: I have around 25 Named Parameters and changing their value everytime i change the repository its too much waste of time. Or keeping in mind all the config details.
Thank you
One way to do this could be: You could store the parameters in a database table (environment,parameter_name, value) and then you have one transformation which accepts a command line argument as input (in this case the environment name). This transformation can then get the parameter names from the database table based on the environment name and then you set these ones as job variables. I guess there are many other ways to achieve the same.
ReplyDeleteCan u please explain that how to schedule a job in windows(local). Please explain in detail.
ReplyDeleteI tried using kitchen/pan,unable to startup both kitchen.bat/pan.bat.
Thanks in advance.
I am not working much with Windows these days. If you cannot execute kitchen and pan, check if you have the rights to execute them.
DeleteNice, this article solves a problem I've been trying to puzzle through for the last couple of hours. Thanks!
ReplyDeleteThanks for your feedback! Glad it was helpful!
DeleteHi
ReplyDeleteCan you please explain , how to upload a jdbc(postgresql) jar in pentaho design studio(pdi-ce-4.2.0-stable), and please explain how to create and test the xaction.
Thanks
Karthik
Can you please clarify if you really mean Pentaho Design Studio (PDS) .. because you also mentioned pdi-ce-4.2.0-stable in your question, which is Pentaho Data Integration.
DeleteSorry it is "pds-ce-win-32-4.0.0-stable".Please explain me that how to create a sample xaction using jdbc and how to test the xaction.
DeletePlease mention me any referal books or video links to know more about pentaho.
Thanks in advance
Karthik
You might want to have a look at the Pentaho Wiki:
Deletehttp://wiki.pentaho.com/display/ServerDoc2x/3.+Action+Sequence+Editor
Here another useful link:
http://blog.datamensional.com/2012/03/xaction-basics-sending-an-email/
Hi Diethard
DeleteCan you please explain how to execute a job in pentaho design studio. i need to pass fdate and tdate as parameters for executing the my job at runtime.
what i have done is :
1.From process actions i add Pentaho Data Integration Job and from the job file i locate the directory and selects my job.
2.now i need to pass the parameters to execute the job, so i added date as fdate and tdate from the process inputs.
Here the problem is that i am unable to provide a default date value for fdate and tdate.
could you plesae explain me in steps
Please correct me if i am questioning wrong.
Thanks in advance
Karthik
I usually schedule my job or transformations as I outlined in this blog post. Can you please let me know why you have to use Xactions for this? What is your exact requirement? Are you trying the schedule your job via the Pentaho BI / BA server?
DeleteActually we have some kettle jobs , we need to run these jobs in Pentaho BI/BA server, And i have to schedule the jobs(need to run these jobs daily at some time intervals).
ReplyDeleteI am very new to penthao , please explain in detail.
Thanks
Karthik
You still haven't told me why you have to set it up directly via the ba server. As said, I never schedule my jobs/transformations via the BA Server. Why can't you just set it up like I outlined above? Is there a specific reason for this?
DeleteIn any case: For an Xaction Introduction have a look at the Pentaho Infocenter: http://infocenter.pentaho.com/help/index.jsp?topic=%2Faction_sequence_guide%2Ftopic_examples.html
Here is how to pass on parameters:
http://infocenter.pentaho.com/help/index.jsp?topic=%2Faction_sequence_guide%2Fconcept_advanced_kettle_vars.html
Hi Diethard ,
ReplyDeleteIssue while calling an PDI job from xaction.
error:- Kettle.ERROR_0004 - The repository specified was not found (Local)
below is my setting.xml file:-
rdbms
Local
Myuser
Mypass
Can you please help me , to enable my BI server find repository settings.
Thanks,
Surya
Please have a look at
ReplyDeletehttp://wiki.pentaho.com/display/EAI/Kitchen+User+Documentation
Sections:
Choose a repository
Set the repository user name
Set the repository password
Select the repository job to run
Or if you run a transformation, look at the Pan docu:
http://wiki.pentaho.com/display/EAI/Pan+User+Documentation
Good luck!
Thanks a ton for reply Diethard ,i can execute job through spoon(cmd too). Job is working fine.When i tried to call this job from kettle repository using "Pentaho Data Integration Job" step in xaction . This says an error "error:- Kettle.ERROR_0004 - The repository specified was not found (Local)" . Bi server unable to find kettle repository setting .
ReplyDeleteCan you help me to set up the setting.
Setting that i changed are : -
settings.xml file under C:\Program Files\pentaho\server\biserver-ee\pentaho-solutions\system\kettle
Changed :-
repository.type to rdbms
repository.name to Local
repository.userid to Myuser
repository.password to Mypass
can you please help me to enable my BI server to find repository settings.
Thanks,
Surya
1) Can you find .kettle\kettle.properties in your user (home) folder?
Delete2) Is the name of the repository exactly the same?
P.S.: I never schedule jobs like this ... I just use crontab on Linux/Unix ... I am not saying that you are doing something wrong, I am just saying that my approach is different ;)
thanks Diethard
ReplyDeleteHi
ReplyDeleteIn my pentaho job i am using FTP step to move my local files to linux server ..It working fine while running locally.but when i am moved that to server and run i am geting error message..
main thing is i want to move files from desktop to server where that job runs in server
can u pls give solution to run this job from server
I thought part of the main reason of using Pentaho is the scheduling feature. Is there any particular reason why it is not being used in this example? Does the PDI CE even come with the scheduling feature?
ReplyDeleteNo, PDI EE only. You can schedule transformations and jobs via the bi-server ce thought, but this is not ideal as it will consume more resources there then.
DeleteAlso there are plenty of other decent scheduling systems out there, it is not really the job of Pentaho to reinvent the wheel!
DeleteHi Diethard ,
ReplyDeleteI can execute a independent scheduled transformation from pentaho DI server console .But issue on running a parametrized scheduled transformation from pentaho DI server console .How can i pass parameter value at run time .
In pentaho BI server , to execute parametrized report we used to pass variable value in URL . tried same in pentho DI server as below
http://localhost:9080/pentaho-di/kettle/startTrans?name=UI_parameter&Values=Testvalue
Hi Diethard,
ReplyDeleteThere is a case in my ETL where i am trying to take "table output" name from command line. The table name does not correspond to any streaming fields name. It will be great if you could suggest me the steps or share some links how should i proceed for the same.
This should be fairly easy: Just create a named parameter for it in your transformation and provide this parameter then via the command line.
DeleteThanks, this help me so much.
ReplyDeleteThanks! I've benn confused with passing value to variables in cmd line for a few days, and this helps me a lot. But I still have some questions and hope you could help in your spare time.
ReplyDeleteI've tried the use of argument and it works fine. But when it comes to variable, there's question. I uses cmd line like this:
"pan /rep:file_repo /trans:CaterOrdersReport 1 7".
The error message is:
"Conversion failed when converting the varchar value '${var_date_start}' to data type int."
But it did works fine in the GUI form, which just exactly the same with mark's above.
The software environment is PDI 7.0 on AWS-Windows server 2012.
Are you using the `Get System Info` step?
DeleteYes, I linked the 'Get system info' step to 'Set variables' step. here is the log and screenshot on Dropbox for your to figure out.https://www.dropbox.com/sh/4u3a53hoxmnwrf6/AACDZ7PwLmoOh9iUXgPlJ-5Da?dl=0.
ReplyDeleteMy reqiurement is how to passing values to variables in scheduling. Thank you very much!
You can't set the variables in the same transformation you use them. If it is possible to create a SQL prepared statement, remove the set variables step and create a direct hob from the get system info step to the table input step. Otherwise, you will have to put the get system info and set variables step into a seperate transformation and run this one before your main transformation so that the variables are available to it (use a job to orchestrate this).
DeleteSorry, Do you mean is 'get system info' is the only way to pass values to variables? I'm new to kettle, I look for the pentaho wiki only getting the named parameter help and nothing about variable. My requriement is define global variables avaliable to all trans and jobs. In other words, define once, use and pass values anytime in any trans, jobs and crontab or cmd schedule. For exmaple, a trans reads raw data within specific period, and writes to excel. A job call the trans and sends the result file in email. I want to define a variable "VAR_FILE_NAME" differing from 'Daily' to 'Weekly'.The trans uses "VAR_FILE_NAME" to create excel file, and the job uses "VAR_FILE_NAME" to make the email title. In this case, which is the apropriate way to defien and pass values to the global variable?
ReplyDeleteWhy don't you just use named parameters?
DeleteBecause named parameter's scope is only confined to one trans or job as far as I know. Is there a way using named parameters globally?
DeleteThey get passed down automatically from the job are transformation you call. Just make sure that the sub-job or sub-transformation does not have the same parameters defined in the settings.
DeleteThank you very much, I am now using this method and it works well. But it's a pity you have to define a parameter twice.
Delete