Pentaho Data Integration: Designing a highly available scalable solution for processing files
Tutorial Details
- Knowledge: Intermediate (To follow this tutorial you should have good knowledge of the software and hence not every single step will be described)
Preparation
The raw data generated each year is increasing significantly. Nowadays we are dealing with huge amounts of data that have to be processed by our ETL jobs. Pentaho Data Integration/Kettle offers quite some interesting features that allow clustered processing of data. The goal of this session is to explain how to spread the ETL workload across multiple slave servers. Matt Casters originally provided the ETL files and background knowledge. My way to thank him is to provide this documentation.
Note: This solutions runs ETL jobs on a cluster in parallel independently from each other. It's like saying: Do exactly the same thing on another server without bothering what the other jobs do on the other servers. Kettle allows a different setup as well, where ETL processes running on different servers can send i.e. the result set to a master (so that all data is combined) for sorting and further processing (We will not cover this in this session).
Preparation
Download the accompanying files from here and extract them in a directory of your choice. Keep the folder structure as is, with the root folder named ETL. If you inspect the folders, you will see that there is:
- an input directory, which stores all the files that our ETL process has to process
- an archive directory, which will store the processed files
- a PDI directory, which holds all the Kettle transformations and jobs
Create the ETL_HOME variable in the kettle.properties file (which can be found in C:\Users\dsteiner\.kettle\kettle.properties)
ETL_HOME=C\:\\ETL
Adjust the directory path accordingly.
Navigate to the simple-jndi folder in the data-integration directory. Open jdbc.properties and add following lines at the end of the file (change if necessary):
etl/type=javax.sql.DataSource
etl/driver=com.mysql.jdbc.Driver
etl/url=jdbc:mysql://localhost/etl
etl/user=root
etl/password=root
Next, start your local MySQL server and open your favourite SQL client. Run following statement:
CREATE SCHEMA etl;
USE etl;
CREATE TABLE FILE_QUEUE
(
filename VARCHAR(256)
, assigned_slave VARCHAR(256)
, finished_status VARCHAR(20)
, queued_date DATETIME
, started_date DATETIME
, finished_date DATETIME
)
;
This table will allow us to keep track of the files that have to be processed.
Set up slave servers
For the purpose of this exercise, we keep it simple and have all slaves running on localhost. Setting up a proper cluster is out of this scope of this tutorial.
Kettle comes with a lightweight web server called Carte. All that Carte does is listen to incoming job or transformation calls and process them. For more info about Carte have a look at my Carte tutorial.
So all we have to do now is to start our Carte instances:
On Windows
On the command line, navigate to the data-integration directory within your PDI folder. Run following command:
carte.bat localhost 8081

Open a new command line window and do exactly the same, but now for port 8082.
Do the same for port 8083 and 8084.
On Linux
Open Terminal and navigate to the data-integration directory within your PDI folder. Run following command:
sh carte.sh localhost 8081
Proceed by doing exactly the same, but now for ports 8082, 8083 and 8084.
Now that all our slave servers are running, we can have a look at the ETL process ...
Populate File Queue
Start Kettle (spoon.bat or spoon.sh) and open Populate file queue.ktr (You can find it in the /ETL/PDI folder). If you have Kettle (Spoon) already running, restart it so that the changes can take effect and then open the file.
This transformation will get all filenames from the input directory (of the files that haven't been processed yet) and stores them in the FILE_QUEUE table.
Double click on the Get file names step and click Show filename(s) … . This should show all your file names properly:

Click Close and then OK.
Next, double click on the Lookup entry in FILE_QUEUE step. Click on Edit next to Connection. Then click Test to see if a working connection can be established (the connection details that you defined in the jdbc.properties file will be used):

Click 3 times OK.
Everything should be configured now for this transformation, so hit the Play/Execute Button.
In your favourite SQL Client run following query to see the records that were inserted by the transformation:
SELECT
*
FROM
FILE_QUEUE
;

Once you inspected the results run:
DELETE FROM FILE_QUEUE ;
The idea is that this process is scheduled to run continuously (every 10 seconds or so).
Define Slave Servers
First off, we will create a table that stores all the details about our slave servers. In your favourite SQL Client run following statement:
CREATE TABLE SLAVE_LIST
(
id INT
, name VARCHAR(100)
, hostname VARCHAR(100)
, username VARCHAR(100)
, password VARCHAR(100)
, port VARCHAR(10)
, status_url VARCHAR(255)
, last_check_date DATETIME
, last_active_date DATETIME
, max_load INT
, last_load INT
, active CHAR(1)
, response_time INT
)
;
Open the Initialize SLAVE_LIST transformation in Kettle. The transformation allows to easily configure our slave server definition. We use the Data Grid step to define all the slave details:
- id
- name
- hostname
- username
- passoword
- port
- status_url
- last_check_date: keep empty, will be populated later on
- last_active_date: keep empty, will be populated later on
- max_load
- last_load: keep empty, will be populated later on
- active
- response_time: keep empty, will be populated later on

As you can see, we use an Update step: This allows us to basically change the configuration at any time in the Data Grid step and then rerun the transformation.
Execute the transformation.
Run following statement in your favourite SQL client :
SELECT * FROM SLAVE_LIST ;
Monitor Slave Servers
Features:
- Checks the status of the active slave servers defined in the SLAVE_LIST
- Checks wether they are still active
- Calculates the load (number of active jobs) per slave server
- Calculates the response time
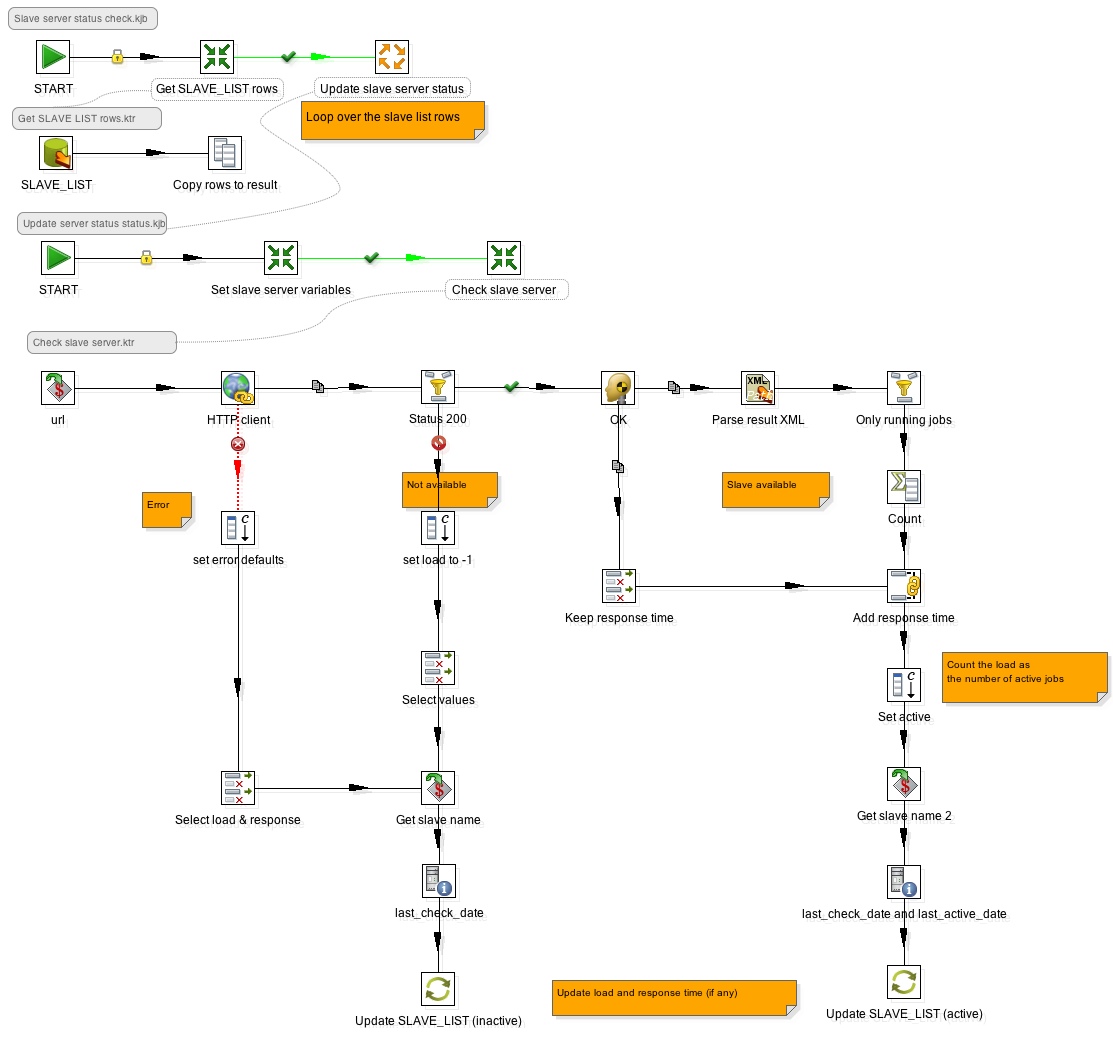
Open following files in Kettle:
- Slave server status check.kjb
- Get SLAVE_LIST rows.ktr: Retrieves the list of defined slave servers (including all details) and copies rows the to the result set
- Update slave server status.kjb: This job gets executed for each input row (=loop)
- Set slave server variables.ktr: receives each time one input row coming from the result set of Get SLAVE_LIST rows.ktr and defines variables for each field, which can be used in the next transformation
- Check slave server.ktr:
- Checks whether the server is not available or status is 200 and then updates the SLAVE_LIST table with an inactive flag and last_check_date.
- If the server is available:
- it extracts the amount of running jobs from the xml file returned by the server
- keeps the response time
- sets an active flag
- sets the last_check_date and last_active_date (both derived from the system date)
- updates the SLAVE_LIST table with this info
Please find below the combined screenshots of the jobs and transformation:
So let's check if all our slave servers are available: Run Slave server status check.kjb. Run the following statement in your favourite SQL client:
SELECT * FROM SLAVE_LIST;
The result set should now look like on the screenshot below, indicating that all our slave servers are active:

Distribution of the workload
So far we know the names of the files to be processed and the available servers, so the next step is to create a job that processes one file from the queue on each available slave server.
Open Process one queued file.kjb in Kettle.
This job does the following:
- It checks if there are any slave servers available that can handle more work. This takes the current and maximum specified load (the number of active jobs) into account.
- It loops over the available slave servers and processes one file on each server.
- In the case that no slave servers are available, it waits 20 seconds.

Some more details about the job steps:
- Any slave servers available?: This fires a query against our SLAVE_LIST table which will return a count of the available slave servers. If the count is bigger than 0, Select slave servers is the next step in the process.
- Select slave servers: This transformation retrieves a list of available slave servers from the SLAVE_LIST table and copies it to the result set.
- Process a file: The important point here is that this job will be executed for each result set row (double click on the step, click on the Advanced tab and you will see that Execute for each input row is checked).
Open Process a file.kjb.

This job does the following:
- For each input row from the previous result set, it sets the slave server variables.
- It checks if there are any files to be processed by firing a query against our FILE_QUEUE table.
- It retrieves the name of the next file that has to be processed from the FILL_QUEUE table (a SQL query with the limit set to 1) and sets the file name as a variable
- It updates the record for this file name in the FILE_QUEUE table with the start date and assigned slave name.
- The Load a file job is started on the selected slave server : Replace the dummy Javascript step in this job with your normal ETL process that populates your data warehouse. Some additional hints:
- The file name is available in the ${FILENAME} variable. It might be quite useful to store the file name in the target staging table.
- In case the ETL process failed once before for this file, you can use this ${FILENAME} variable as well to automatically delete the corresponding record(s) from the FILE_QUEUE table and even the staging table prior to execution.
- Note that the slave server is set in the Job Settings > Advanced tab:
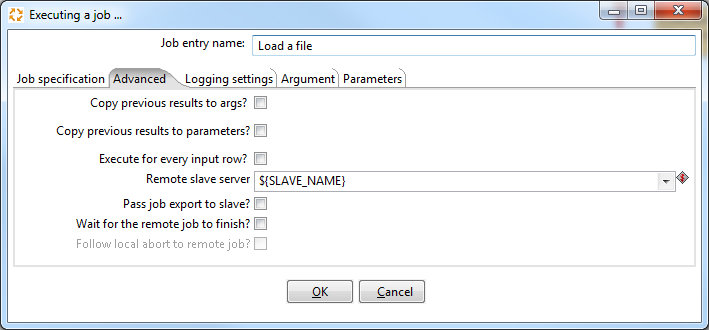
- If the process is successful, the record in the FILE_QUEUE table gets flagged respectively. The same happens in case the process fails.
Test the whole process
Let's verify that everything is working: Open Main Job.kjb in Kettle and click the Execute icon.
Now let's see if 4 files were moved to the archive folder:

This looks good ... so let's also check if our FILE_QUEUE table has been updated correctly. Run following statement in your favourite SQL client:

Note that the last file (file5.csv) hasn't been processed. This is because we set up 4 slave servers and our job is passing 4 files to each of the slave servers. The last file will be processed with the next execution.