Kettle Transformation Logging and Change Data Capture
Updated Version including the great feedback from Matt Casters and Jos (both authors of the fantastic "Kettle Solutions" book)
Sample File
Tutorial Details
- Knowledge: Intermediate (To follow this tutorial you should have good knowledge of the software and hence not every single step will be described)
- Tutorial files can be downloaded here
CDC
In this session we will look at the extensive Pentaho Data Integration/Kettle 4.1 logging features. Now how come we also talk about Change Date Capture (CDC)? This is because Kettle incorporates logging of the start and end date for CDC in the logging architecture.
If you are not familiar with CDC, here a brief summary: CDC allows you to capture all the data from the source system that has changed since the last time you ran the ETL process. Wikipedia gives a more detailed overview in case you are interested. In the easiest case you have some sort of timestamp or datetime column that you can use for this purpose. The following example will be based on a simple sales table that has a date column which we can use for CDC:

Note that this is dataset has actually quite old data, something that we have to keep in mind. What happens if new data gets inserted later on? More on this after the basics.
Open your favourite SQL Client (and start your MySQL server if it is not running yet) and issue following SQL statements:
USE
test
;
DROP TABLE IF EXISTS
`sales`
;
CREATE TABLE
`sales`
(
`date` DATETIME,
`product_type` VARCHAR(45),
`sales` INT(255)
)
;
INSERT INTO
`sales`
VALUES
('2010-01-20 00:00:00','Shoes',234),
('2010-01-20 00:00:00','Cheese',456),
('2010-01-21 00:00:00','Shoes',256),
('2010-01-21 00:00:00','Cheese',156),
('2010-01-22 00:00:00','Shoes',535),
('2010-01-23 00:00:00','Cheese',433)
;
SELECT
*
FROM
`sales`
;
Now the way to get the timeframes for querying the data is to use the Get System Info step:
- Open Kettle and create a new transformation
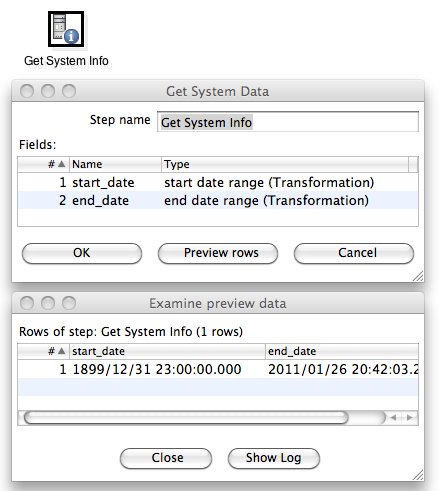
- Drag and drop a Get System Info step on the canvas. You can find it in the Input folder.
- Double click on it and populate the names column in the grid with start_date and end_date.
- For the type choose start date range (Transformation) and end date range (Transformation) respectively
Click on Preview rows and you will see that Kettle displays a rather old datetime for the startdate (1899/12/31 23:00:00) and the current datetime for the enddate. Now this makes perfectly sense as with first run of your transfromation you want to get all the raw data from your source system. In case you don’t want this, I’ll show you a trick later on on how to change this.
Now this is an easy approach for CDC. You can feed the start and end date from the Get System Info step to a Table Input step in example and use the start and end date in the WHERE clause of your SQL query:
SELECT
date
, product_type
, sales
FROM sales
WHERE
date>=? AND
date<?
;
The question marks will be replaced on execution by the start and end date (but make sure they are defined in this order in the Get System Info step).
Let's add some more steps to our transformation:
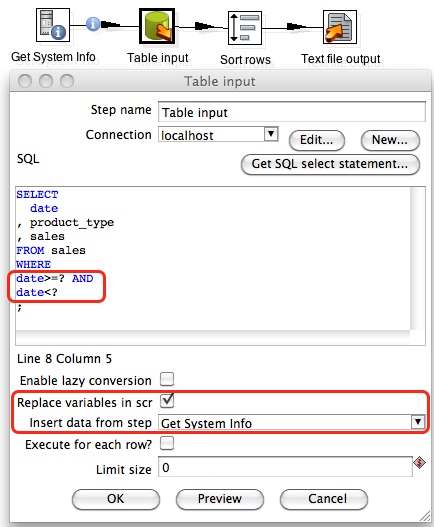
Make sure that you enable Replace variables in script? and choose the Get System Info step for Insert data from step. The hop between the Get System Info step and the Table Input step now also displays an info icon.
Setting up Logging
Kettle provides various levels of logging, the transformation logging being the one with the highest level. We will only look at the transformation logging here.
- Press CTRL+T and the Transformation properties dialog will be displayed.
- Click on the Logging tab and then highlight Transformation on the left hand side.
- Our log will be placed in a database table, hence provide the info for the data connection and table name.
- We only want to keep the log records for the last 30 days, hence we set Log record timeout (in days) to 30.
- It’s best to keep all the logging fields (less maintenance)
- Provide step names for some of the fields, in example:
- LINES_INPUT: specify the input step that represents the amount of imported data best.
- LINES_OUTPUT: specify the output step that represents the amount of imported data best
- Press the SQL button and Kettle will automatically generate the DDL (the create table statement) for you. Just press Execute and your logging table will be created on your specified database. Nice and easy!
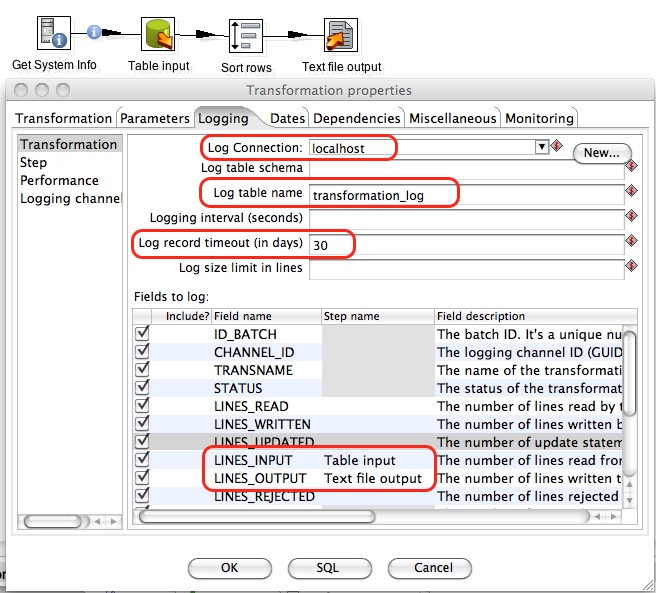
So now we are all set and can run our transformation and see what’s happening. Click the Play button to execute the transformation. If your transformation executed successfully, close the transformation and open it again, then on the bottom click on the Execution History tab and you will so the logging information. (Kettle automatically reads the data from the table we just created).

Now pay attention to the Date Range Start and Date Range End field: It includes the data from our Get System Info step. Now execute the transformation again and see what happens (Click the Refresh button):
- You can clearly see that Kettle new choose the CDC end datetime (which is the start datetime) of the last transformation execution for the start date. The last transformation execution has the Batch ID 0 in the screenshot above.
- The CDC end date is set to the start date of the current transformation execution.
A safe approach to CDC
The CDC approach mentioned above is actually quite dangerous if your source data table doesn't get filled consistently. A safer approach is to use the maximum date of your source data as the CDC end date. Kettle provides this functionality out of the box: In the Transformation properties you can find a Dates tab. Click on it and provide following details of your fact table:
- Maxdate Connection: the database connection
- Maxdate table: the table name of your source table
- Maxdate field: the datetime field in your source table that you use for CDC
- Maxdate offset (seconds): If there are some inconsistencies in your source data, you can set a negative offset here. In example: -120 means that 120 seconds will be deducted from the max end date for CDC
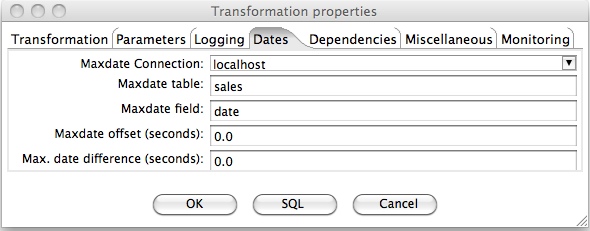
As you can see from the screenshot above, I referenced again our main input table. So whatever the maximum date in this table is, Kettle will now use it for CDC. Open MySQL Client and delete all the records from our transformation log table, then start the transformation. As you can see from the Execution History Kettle now use the maximum date of our data set.

What more to say? Well, if you are unhappy with the first timeframe that Kettle chooses, just run the transformation once without any raw data input step, open a SQL client and update the end date with a date of your liking (this end date should be the start date that you want for the next execution). The next time you run your transformation, this datetime will be used for the start of your timeframe.
Hi Didi,
ReplyDeletenice post, but I would be a bit more cautious with using the end date of the last transformation as the start date of the new one. If the load starts at time x and ends at time x+1, you run the risk of missing the changes that have been made between x and x+1. This is the reason why in these cases (timestamp based CDC) I set the time stamp for the next load at the start of the current load (see also chapter 6 of Pentaho Kettle Solutions for an example)
best, Jos
Hi Jos. Many thanks for your feedback. As far as I understood kettle will automatically provide the start and end date based on the last time the transformation ran and the execution start time of the current transformation. Am I missing something? The last bit that I described in the article was just a hack in case you are not happy with the first start time that kettle provides by default with the very first run (were you referring to this?).
ReplyDeleteYou didn't mis anything Diethard. For those cases where x+1 is too close to the horizon because of inconsistencies in the source system, you can set a negative off-set in the Dates tab of the transformation settings dialog. For example specifying -120 would set the end-date to T(x+1)-120s.
ReplyDeleteFor whole sets of transformations that need to be run consistently with the same date range you can perform the same trick on the job level, set a few variables and use those for CDC.
Finally, if that doesn't cut it make sure to never forget you can *obviously* create and maintain your own logging tables in a job or transformation.
HTH,
Matt
Thanks a lot Matt for the clarification! Much appreciated!
ReplyDeleteSo I checked this again and yes, Kettle logs the start time of the transformation as the end time for the CDC. So the off-set would only be necessary if the source table doesn't have the data up to this time and this is a constant problem. If the problem is not constant, i.e. due to technical problems, data didn't get imported into the table, well then I assume a custom CDC logging table will be necessary. Or is there a some automatic function within the Kettle logging mechanism that could detect a data delay in the source table and adjust end time accordingly (let's say the table has only data up until 2011-01-28 10:01:01 and the transformation runs at 2011-01-28 10:10:00)?
That's where the max-date table & field comes in (the Date tab). If that table only has data up until 2011-01-28 10:01:01 the end of the date range will be that.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteThanks a lot Matt for your help! I tried this out now and it's a working excellently! I updated my article.
ReplyDeleteBest regards,
Diethard
I'm sorry if this isn't the correct place to ask, but is it possible to use these CDC features within KFF?
ReplyDeleteI was looking at the documentation for setting up KFF, and I didn't see any way to do so with a DB repository.
I didn't have a chance yet to look at the latest KFF developments, so for not, unfortunately, I cannot answer your question. I'll try to get up-to-date on the KFF project in the next few weeks (It's quite a promising project).
ReplyDeleteI really liked the idea of having CDC and logging out of the box with Pentaho.
ReplyDeleteBut ... it's annoying not to have step start/end time logged in database.
How can we analyze the performance without knowing the duration of each atomic steps inside the transformation.
Execution time of the entire transformation can be calculated by deducting "Date range end" from "Log date".
Unfortunately it's not enough for us:(
Thus we need to develop and maintaint our own logging tables.
Also we could have some performance issues with the CDC model.
It looks nice for some simple deployment.
But my case is: tons of steps to be tracked, near realtime DW with continous ETL execution, statistics are very important, so no truncation.
In this way we generate thousands of rows in logging table per day, millions per month.
Sure we can move some old rows to a separate aggregated table and delete them.
Anyway this is not enough unless Pentaho stores the "Date range end" somewhere else?
Actually it looks like the only place is the database, because if I disable the logging to DB the CDC will not work.
Thus Pentaho uses max to find the last valid "Data range end" from previous execution and this is not very nice.
So again we need to build and maintain our own CDC tables.
Regards,
Andrius
Well, the out-of-the-box functionality is for simple use cases. If you require a more complex logging for CDC, you will have to create it yourself. Also not all CDC techniques are time based, so there is no out-of-the-box functionality for this case in Kettle either. Understandably, as the logic can sometimes be quite complex. It's not too difficult though to create it yourself.
DeleteI am not too sure what your refer to with "How can we analyze the performance without knowing the duration of each atomic steps inside the transformation." This sounds like another pair of shoes to me, not really related to CDC: If you want to log the performance of each step within your transformation, you can enable this via the standard logging settings. Hope this helps.
Check the the step logging screen. There is just "Log date" of date type.
Delete"Step start ", "Step end", "Duration" do not exist in here.
So we do not know how much time took to execute the step.
Unless you see this on some diff version? I have 4.3.0.
Well, all transformation steps are executed in parallel. If you want to understand which step is slowing down your transformation, one of the main things to watch out for is the throughput.
DeleteThat's not a friendly way to do so. I cant tell what's wrong just looking at the throughput. There could be a step having 10000r/s because of large load or 100r/s by complex calculation which is already tuned up to the max.
DeleteSo you need to compare against previous execution to find out what step is making troubles.
This comparison will be valid only if rowcount is the same and day/week/hour time is similar. If not then you are in deep.
I dont have time for these games. It needs to be automated which is not possible with this tool at the moment.
Even though all steps are started in parallel, in reality they do nothing until From steps finish their work. (for example aggregation). But the way pentaho starts all steps in parallel spoils the statistics completely.
Well I understand that complex deployment requires more sophisticated tools.
And I just wanted to check how much of this is doable with pentaho.
Well I normally use a given fixed data set for testing. I try to tune the steps by observing the throughput and also looking at the total execution time (among others). It's a game, yes, but it's fairly straight forward as you can do all via the GUI (Spoon) and can quickly understand what's going on.
DeleteAll steps start in parallel (waiting for the data to arrive). And yes, some steps are specific, like joins, because they need to have all the data first before they can pass it on.
You right. It's enough for development.
DeleteBut when we deploy the solution it should switch to fully automated mode.
No GUI just email or other type of notifications send by the ETL engine.
Is join a blocking transformation in Pentaho?
I guess in SSIS "one to one" join doesnt block the flow. It release the row as soon as pair is found.
What I forgot to say is - thanks for the great post. It's really useful and handy. I found it very easy to setup and test by reading your blog.
That's what I like about Pentaho - getting started easily. And this was my first day with Pentaho ;)
Thanks again.
Once the lookup/join data is available it should just release the row.
DeleteYou can also set up email notifications etc. So you can set up your process to monitor the log and in case something unexpected happens get notified by email.
Thanks a lot for your feedback, much appreciated!
If you want to learn quickly more about Kettle, check out Maria's book: http://www.packtpub.com/pentaho-data-integration-4-cookbook/book
Andrius, maybe you've just learnt this by now, but performance analysis is made using the performance step logging. After having data you must - pretty much like GUI - look for steps with high input buffer and zero or little output buffer. This is the bottleneck signature.
ReplyDeleteI am finding that in Pentaho 4.3, it looks like the Transformation is hanging trying to get a LOCK on the transformation log table. Anyone know if this is a known issue.
ReplyDeleteAs I am not familiar with your setup, I can only recommend filing a jira case on jira.pentaho.com in case you think it's a bug.
DeleteHi,
ReplyDeleteI would like to implement Kettle JOB Logging and Change Data Capture(Safe approach)
Can Any one please help me on this ..
Thanks In Advance
Ravan
Setting up the logging for jobs is similar to setting it up for transformations, so this should be fairly straight forward. There is no built-in option to set up CDC on a job level. If your CDC requirements are not that simple (and often they are) you will have to create your own solutions for it i.e. using some transformations that you link together in a job.
DeleteThanks for Quick Response Diethard
DeleteI didn't the dates tab to maintain max date feild & table name JOB level
Can we use the same log table for the whole JOB(Multiple Transformations)
I see an options in Get Sytem Info(start date range(job),end date range(job))
Fyi -- I am using Kettle 4.3
Well, the logging tables (as the one set up in this tutorial) are for all transformations [if you use the same name for the logging table] (and if you set them up for a job as well they are available for all jobs). It's worth having a look at this table to understand what is stored in it ... you will see that there is a transformation name in it as well. So if you use the built-in CDC in more than one independent transformation, then it should work like this. Obviously, always test your setup!
ReplyDeleteI am not too sure what you mean by CDC on a job level ... the built in CDC functionality is normally defined on a transformation level. So if you have more independent fact transformations, then you have to define the built-in CDC for each of them.
But as said before, this is just a very simple CDC logging ... I hardly ever use it because usually my requirements are more complex.
Thanks A Lot Diethard:)
ReplyDeleteIts Working ...
You are welcome!
DeleteIs there a way to provide variables for 'Maxdate table' and 'Maxdate field' fields?
ReplyDeleteOnly fields that have a $ icon next to them accept variables.
DeleteFirstly, apologies - I know this is an old post but it's the best fit to what I'm trying to achieve.
ReplyDeleteSecondly, I'm relatively new to PDI, having just started development with it a couple of months ago. Although, it's such a great tool that I managed to deliver some 3 or 4 integration projects during this time.
Now straight to business: I have a job which I need to loop through the same set of transformations for every site (same db schema across the country) for which I'm bringing data into a data warehouse. Everything is done dynamically at job level to make sure that connections and other pieces of config are switched to the next site every time one is finished until I run through all of them.
The only thing I cannot change are the transformation names, because they won't accept variables. The problem here is that I absolutely love and depend on the out of the box logs for the built-in CDC feature to work, and it uses the transformation names to keep track of star/end dates. I have to record this at transformation + site level, because they will sometimes run at different times of the day (in case of comms having been down, for example).
The only way I could find around this was physically creating copies of the whole set of transformations for each site, manually renaming them (adding site name) and running one job for each site. But this makes maintenance/enhancements a pain in the butt, because it means applying that tiny small change 10 times. Deployment to QA and Prod is also very painful.
Does anyone have ever gone through this same problem? Suggestions?
This AWESOME blog has been favourited :) Keep up with the good tips!
Thanks a lot.
Thanks for your feedback. Yes, I see this is quite cumbersome. In such a case I would usually create an additional custom logging table. If you want to stick with the PDI log only, one option would be to write to site name into log. This is not ideal when retrieving the info with a SQL query, because parsing the log field might be quite performance intensive, but it works. You could just use a regex in your SQL query to extract the value.
DeleteAlternatively, you could also create a fairly empty job whose job name includes the site name. This job is called by the main job, has no logic included other than calling the generic transformations. This makes it easier to query the log info. There might be some other options as well ...
Thanks Diethard.
DeleteI'm actually considering the two options and going for a hybrid approach ;)
This comment has been removed by the author.
ReplyDeleteA great tutorial. Just what i wanted. However, my transformation fails to run. Iam getting the error "Data truncation: Incorrect datetime value: '1900-01-01 04:30:00' for column 'STARTDATE' at row 1"
ReplyDeleteMy kettle job is exactly the way it is described here.
I have two variables "start_date_range" and end_date_range" varaibles and iam following the second CDC approach where i want my max date to come from my sql table.
Any suggestions? What am I doing wrong??