Pentaho Data Integration: Remote execution with Carte
Tutorial Details
- Knowledge: Intermediate (To follow this tutorial you should have good knowledge of the software and hence not every single step will be described)
Carte is an often overlooked small web server that comes with Pentaho Data Integration/Kettle. It allows remote execution of transformation and jobs. It even allows you to create static and dynamic clusters, so that you can easily run your power hungry transformation or jobs on multiple servers. In this session you will get a brief introduction on how to work with Carte.
Now let's get started: SSH to the server where Kettle is running on (this assumes you have already installed Kettle there).
Encrypt password
Carte requires a user name and password. It's good practise to encrypt this password. Thankfully Kettle already comes with an encryption utility.
In the PDI/data-integration/ directory run:
sh encr.sh -carte yourpassword
OBF:1mpsdfsg323fssmmww3352gsdf7
Open pwd/kettle.pwd and copy the encrypted password after "cluster: ":
vi ./pwd/kettle.pwd
# Please note that the default password (cluster) is obfuscated using the Encr script provided in this release
# Passwords can also be entered in plain text as before
#
cluster: OBF:1mpsdfsg323fssmmww3352gsdf7
Please note that "cluster" is the default user name.
Start carte.sh
Make sure first that the port you will use is available and open.
In the simplest form you start carte with just one slave that resides on the same instance:
nohup sh carte.sh localhost 8181 > carte.err.log &
After this, press CTRL+C .
To see if it started:
tail -f carte.err.log
Although outside the scope of the session, I will give you a brief idea on how to set up a cluster: If you want to run a cluster, you have to create a configuration XML file. Examples can be found in the pwd directory. Open one of these XMLs and amend it to your needs. Then issue following command:
sh carte.sh ./pwd/carte-config-8181.xml >> ./pwd/err.log
Check if the server is running
Issue following commands:
[root@ip-11-111-11-111 data-integration]# ifconfig
eth0 Link encap:Ethernet HWaddr ...
inet addr:11.111.11.111 Bcast:
[... details omitted ...]
[root@ip-11-111-11-111 data-integration]# wget http://cluster:yourpassword@11.111.11.111:8181
--2011-01-31 13:53:02-- http://cluster:*password*@11.111.11.111:8181/
Connecting to 11.111.11.111:8181... connected.
HTTP request sent, awaiting response... 401 Unauthorized
Reusing existing connection to 11.111.11.111:8181.
HTTP request sent, awaiting response... 200 OK
Length: 158 [text/html]
Saving to: `index.html'
100%[======================================>] 158 --.-K/s in 0s
2011-01-31 13:53:02 (9.57 MB/s) - `index.html' saved [158/158]
If you get a message like the one above, a web server call is possible, hence the web server is running.
With the wget command you have to pass on the
- user name (highlighted blue)
- password (highlighted violet)
- IP address (highlighted yellow)
- port number (highlighted red)
Or you can install lynx:
[root@ip-11-111-11-111 data-integration]# yum install lynx
[root@ip-11-111-11-111 data-integration]# lynx http://cluster:yourpassword@11.111.11.111:8181
It will ask you for user name and password and then you should see a simple text representation of the website: Not more than a nearly empty Status page will be shown.
Kettle slave server
Slave server menu
Show status
Commands: Use arrow keys to move, '?' for help, 'q' to quit, '<-' to go back.
Arrow keys: Up and Down to move. Right to follow a link; Left to go back.
H)elp O)ptions P)rint G)o M)ain screen Q)uit /=search [delete]=history list
You can also just type the URL in your local web browser:
http://ec2-11-111-11-111.XXXX.compute.amazonaws.com:8181
You will be asked for user name and password and then you should see an extremely basic page.
Define salve server in Kettle
- Open Kettle, open a transformation or job
- Click on the View panel
- Right click on Slave server and select New.
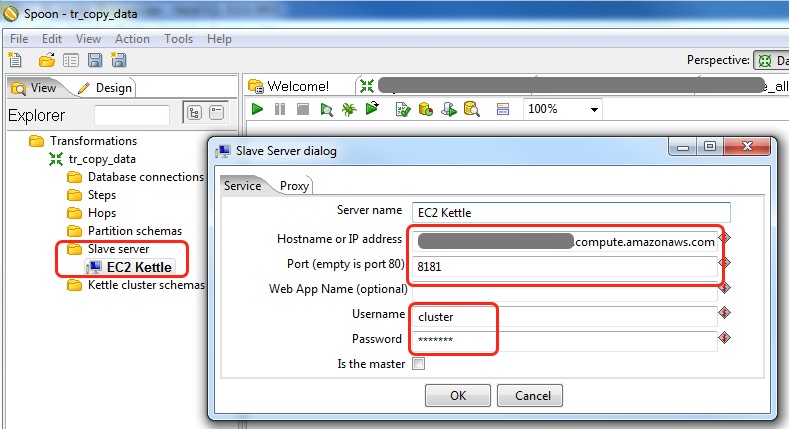
Specify all the details and click OK. In the tree view, right click on the slave server you just set up and choose Monitor. Kettle will now display the running transformations and jobs in a new tab:

Your transformations can only use the slave server if you specify it in the Execute a transformation dialog.
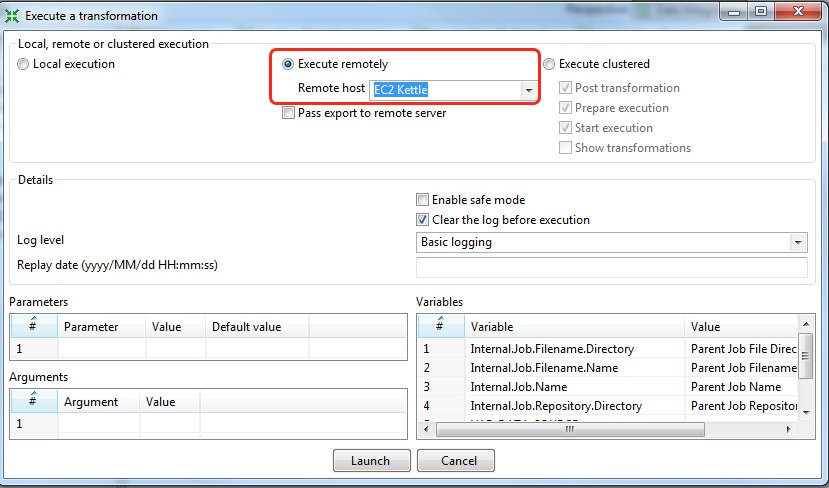
For jobs you have to specify the remote slave server in each job entry dialog.
If you want to set up a cluster schema, define the slaves first, then right click on Kettle cluster schemas. Define a Schema Name and the other details, then click on Select slave servers. Specify the servers that you want to work with and define one as the master. A full description of this process is outside the scope of this article. For further info, the "Pentaho Kettle Solutions" book will give you a detailed overview.
For me a convenient way to debug a remote execution is to open a terminal window, ssh to the remote server and tail -f carte.err.log. You can follow the error log in Spoon as well, but you'll have to refresh it manually all the time.