Prerequisites:
- Current version of PDI installed.
Navigate to the PDI root directory. Let’s start three local carte instances for testing (Make sure these ports are not in use beforehand):
sh carte.sh localhost 8077
sh carte.sh localhost 8078
sh carte.sh localhost 8079
In PDI Spoon create a new transformation.
Click on the View tab on the left hand side and right click on Slave server and choose New. Add the Carte servers we started earlier on one by one and define one as the slave server. Note the default carte user is cluster and the default password is cluster.

Next right click on Kettle cluster schemas and choose New.
Provide a Schema name and then click on Select slave servers. Mark all of them in the pop-up window and select OK.

Next we want to make sure that Kettle can connect to all of the carte servers. Right click on the cluster schema you just created and choose Monitor all slave servers:

For each of the servers Spoon will open a monitoring tab/window. Check the log in each monitoring window for error messages.

Additional info: Dynamic clusters
If the slave servers are not all known upfront, can be added or removed at any time, Kettle offers as well a dynamic cluster schema. A typical use case is when running a cluster in the cloud. With this option you can also define several slave servers for failover purposes. Take a look at the details on the Pentaho Wiki.
|
If Kettle can connect to all of them without problems, proceed as follows:
How to define clustering for a step
Add a Text input step for example.
Right click on the Text input step and choose Clustering.
In the Cluster schema dialog choose the cluster schema you created earlier on:

Click OK.
Note that the Text input step has a clustering indicator now:

Note: Only the steps that you assign the cluster schema this way will be run on the slave servers. All other ones will be run on the master server.
Our input dataset:
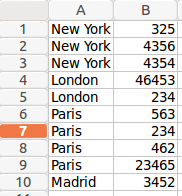
Creating swimlanes
In this example we will be reading the CSV files directly from the slave servers. All the steps will be executed on the slaves (as indicated by the Cx2).

To run the transformation on our local test environment, click the execute button and choose Execute clustered:

The last option Show transformations is not necessary for running the transformation, but helps to understand how Kettle creates individual transformations for your slave servers and master server in the background.
As we test this locally, the results will be read from the same file twice (we have two slave servers running locally and one master server) and will be output to the same file, hence we see the summary twice in the same file:

Debugging: Observer the logs of the slave and master servers as the main transformation log in Spoon (v4.4) doesn’t seem to provide you an error logs/messages in clustered execution. So always monitor the server logs while debugging!
Preview: If you perform preview on a step, a standard (non-clustered) transformation will be run.Summarizing all data on the master
Now we will change the transformation so that the last 3 steps run on the master (notice that these steps do not have a clustering indicator):

If we execute the transformation now, the result looks like this:

So as we expect, all the data from all the slaves is summarized on the master.
Importing data from the master
Not in all cases will the input data reside on the slave servers, hence we will explore a way to input the data from the master:

Note that in this case only the Dummy step runs on the slave server.
Here is the output file:

So what happens is that the file will be input the data on the master, records will be distributed to the dummy steps running on the slave server and then aggregated on the master again.
My special thanks go to Matt and Slawo for shedding some light into this very interesting functionality.
Great blog post Diethard, I'm a fan!
ReplyDeleteAs an extra tip for the "importing data from the master" section, for even better performance, sort on the slave servers and then use a "Sorted Merge Rows" step to keep the rows sorted when they end up on the master.
Cheers,
Matt
Thanks a lot Matt! Your feedback is highly appreciated! I am planing to make use of this example in my next blog post which will be dealing with partitioning data on the cluster. It's a very interesting topic!
DeleteHi Dieter,
ReplyDeletethanks for your great post. It appears, that the "Get File Names" Step is necessary to prevent Kettle from splitting up the input file on its own. Due to performance reasons I need to use the CSV Input Step, which doesnt give me the possibility to get the file name dynamically from the "Get File Names" step. Do you have any idea on this one?
Thanks in advance,
Andreas
Well, the purpose of the "Get File Names" Step is only to pass down all the available file names to the main transformation flow, nothing else.
DeleteYes, the CSV Input step works differently. You can create another transformation that gets the file names upfront and then have the main transformation loop over this filename result set (the CSV input step has to accept a filename variable in this case).