Pentaho Data Integration: Full Outer Joins
Creating full outer joins in Pentaho Data Integartion (PDI aka Kettle) is a fairly straight forward approach ... let’s have a look at it:
In this example we will be looking at data of an online acquisition process. We are facing the problem that the tracking hasn’t been implemented correctly, hence it can happen, that in a few cases we have pin insertions but no page impressions.
This is a good example to use a full outer join, as we will preserve all the data and can demonstrate to management that there is indeed a problem with the tracking setup.
Imagine we have two simple data sets:
Page Impressions
date
|
service
|
mk
|
page impressions
|
2010-05-01
|
serv1
|
123
|
231
|
2010-05-01
|
serv2
|
443
|
2
|
2010-05-01
|
serv3
|
234
|
33
|
PIN Insertions
date
|
service
|
mk
|
pin insertions
|
2010-05-01
|
serv5
|
33
|
231
|
2010-05-01
|
serv2
|
443
|
1
|
2010-05-01
|
serv1
|
123
|
55
|
Ok, let’s get started: Copy the above data sets into two separate Excel spreadsheets, save the file and fire up PDI/Kettle.
Create a new transformation. First thing to do in Kettle is to drag and drop an Excel Input step (you can find in in the Input folder in the Design tab on the left hand side). Double click on it. Click on “Browse” and choose the file that we just saved. Click “Open”. The file dialog closes, then click on “Add” (next to “Browse”).

Next click on the “!Sheets” tab followed by clicking on “Get Sheetnames”. Mark the sheet name that contains the page impressions, then click “>” to add it to your selections. It should look like this now:
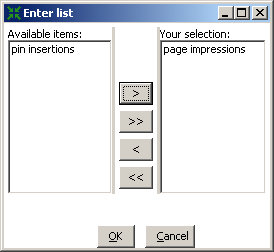
Click “ok”.
Go to the “!Fields” tab and click on “Get fields from header row(s) ...”:
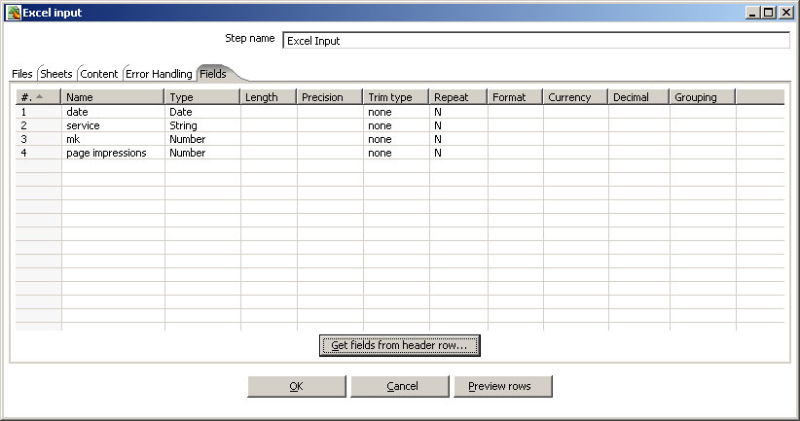
Now we are ready to view the data: Click on “Preview Rows” and check if everything is alright.
Close the preview window and click “ok” to close the step window.
Now mark the “Excel Input” step and copy and paste it. Open the new step and change it so that it imports the other spreadsheet. Make sure that you change the sheet name and the field names! Preview the data to see if everything is ok.
We now add a sort step for each of the Excel Input steps. Connect the Excel Input steps and the Sort Steps with a hop by holding down SHIFT and drawing a line from one step to the other.
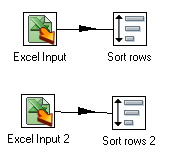
Open the Sort Step and click on “Get fields ...”. Mark the row that contains “page impressions” or “pin insertions” and press DELETE (we obviously don’t want to sort by the measure). Click “Ok”. Do exactly the same for the other Sort Step.
As we have now sorted our data sets, we can join them. Drag and drop a Merge Join Step onto the canvas and connect both Sort Steps to it.
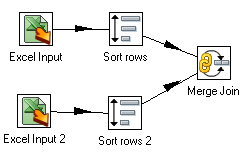
Open the Merge Join Steps, set the first step to “Sort Rows” and the second step to “Sort Rows 2” and join type to “Full Outer”. As we use a full outer join, it isn’t really important which step you mention in first step or second step.
Now click on “get key fields” and delete the measures. It should look like this now:
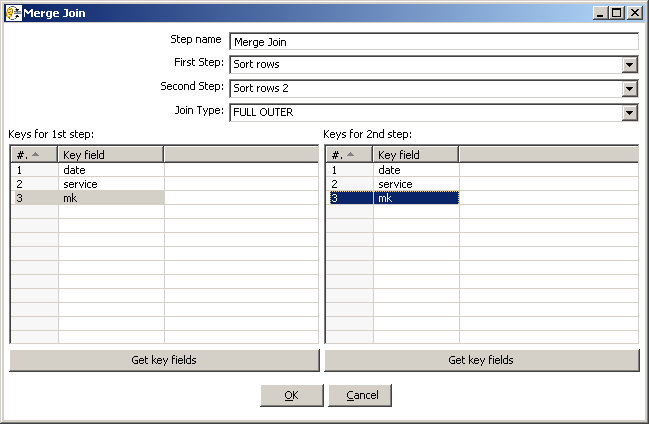
Now it is a good idea to preview the data again. Mark the Merge Join step and press F10. In the “Transformation Debug Dialog” click on “Quick Launch”.

You see that Kettle has successfully joined the data sets. As we chose “Full Outer” as join type, we can see all the data from each input data set. You will also realize, that both data sets had field names in common, so Kettle added “_1” to the field names of the second data set to avoid any confusion.
So now let’s clean up this result set a bit, to make it look nicer. We will add new fields called date_king, service_king and mk_king, and will use the values date or date_1 ( and so on) to populate it. The goal is to have for each row a proper date, service and mk value.
Add a Formula step and connect the Merge Join step to it. Fill out the Formula step as shown in the screenshot below:

Here the formulas to copy:
IF(ISBLANK([date]);[date_1];[date])
IF(ISBLANK([service]);[service_1];[service])
IF(ISBLANK([mk]);[mk_1];[mk])
What we do here is to check if one of the fields is empty and if yes, we use the value of the other one.
Click “Ok” to close the step configuration.
Now do a quick preview by clicking on the step and pressing F10.

As we don’t want to have all the unnecessary data in our final result set, add a “Select values ...” step, create the hob and open the configuration window of this step. Click on “Get fields to select” and delete all fields except the ones shown in the screenshot below:
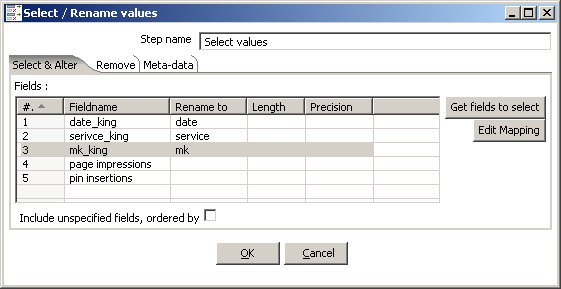
We also rename some of the fields and put them in a different order. Ordering works like this: Mark the row, press ALT and use the arrows to move the row to another position.
Press F10 again and now the result set should look like this:

Now everything looks pretty and nice. If you want to export the result set somewhere, feel free now to add one of the many export steps.
This is how to create an Outer Join in Kettle in a nutshell. I think you will agree with me in saying that this is fairly easy to achieve.
I'm looking for this, it works for me,..thank you so much
ReplyDeleteYou are welcome! Good to hear that the article could help you!
ReplyDeleteis there any advantages / disadvantages in using Stream lookup step instead of merge join step ?
ReplyDeleteYes, with the Stream lookup the data keeps on flowing in your main stream and retrieves the lookup data on the go, whereas with the merge join step, all the data has to first arrive there, only then the join will be performed. The stream lookup is more suitable for a smaller lookup dataset, as the lookup dayta will be cached.
Delete