Kettle Test Framework (KTF)
Subtitle: Kettle Testing for the Non-Java Developers
Announcing the KTF Beta:
Precautions
Please note that KTF is still in Beta and has undergone only minimal testing. Please report any bugs on the dedicated Github page so that they can be easily fixed for everybody’s advantage. Do not use for any production purposes.
You must not run this process on a production environment! You should only run this process on a dedicated test environment where it is ok to lose all the data in the database. You must run this process on a dedicated test database! This process wipes out all your tables!
The small print upfront
Please note that this is a community contribution and not associated with Pentaho. You can make use of this framework at your own risk. The author makes no guarantees of any kind and should not be hold responsible for any negative impact.
You should have a solid understanding of Pentaho Data Integration/Kettle. I made a minimal attempt to document this framework - the rest is up to you to explore and understand.
Motivation
The main idea behind this framework is to create a base for best test practises in regards to working with the Kettle ETL tool. Please add any ideas which could improve this test framework as “improvement” on the dedicated Github page.
Testing data integration processed should be core part of your activities. Unfortunately, especially for non Java developers, this is not quite so straightforward (Even for Java developers it is not quite that easy to unit test their ETL processes, as highlighted here.). This framework tries to fill this gap by using standard Kettle transformations and jobs to run a test suite.
When you create or change a data integration process, you want to be able to check if the output dataset(s) match the ones you expect (the "golden" dataset(s)). Ideally, this process should be automated as well. By using KTF's standard Kettle transformations and jobs to do this comparison every data integration architect should be in the position to perform this essential task.
When you create or change a data integration process, you want to be able to check if the output dataset(s) match the ones you expect (the "golden" dataset(s)). Ideally, this process should be automated as well. By using KTF's standard Kettle transformations and jobs to do this comparison every data integration architect should be in the position to perform this essential task.
Some other community members have published blog posts on testing before, which this framework strongly took ideas/inspiration from (especially Dan Moore’s excellent blog posts [posts, github] ). Also, some books published on Agile BI methodologies were quite inspirational (especially Ken Colliers “Agile Analytics”) as well.
While Dan focused on a complete file based setup, for now I tried to create a framework which works with processes (jobs, transformations) which make use of Table input and Table output steps. In the next phase the aim is to support file based input and output (csv, txt) as well. Other features are listed below.
Contribute!
Features
Let’s have a look at the main features:
- Supports multiple input datasets
- Supports multiple output datasets
- Supports sorting of the output dataset so that a good comparison to the golden output dataset can be made
- The setup is highly configurable (but a certain structure is enforced - outlined below)
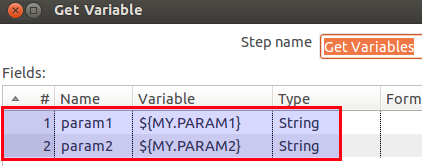
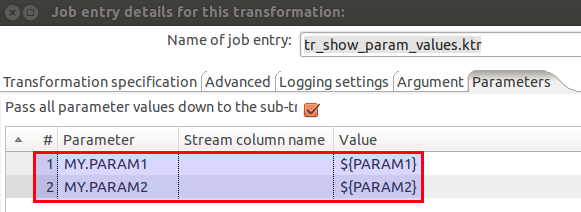
- Non conflicting parameter/variable names (all prefixed with “VAR_KTF_”)
- Non intrusive: Just wraps around your existing process files (except some parameters for db connections etc will have to be defined … but probably you have this done already anyways)
Current shortcomings
- Not fully tested (only tested with included samples and on PostgreSQL)
- Currently works only with Table input / output transformations. Text/CSV file input/output will be supported in a future version (which should not be too complicated to add).
- Dictates quite a strict folder structure
- Limited documentation
Project Folder Structure

Stick to this directory layout for now. In future versions I might make this more flexible.
- Adjust parameter values in config/.kettle/kettle.properties and JNDI details in config/simple-jndi/jdbc.properties
- Your transformations have to be prefixed for now with “tr_” and your jobs with “jb_”. Do not use any special characters or spaces in your job/transformation names. Your transformations and jobs have to be saved within repository/main. There is currently now subfolder structure allowed within this folder.
- Within the config/test-cases directory create a folder for the processes you want to test. A process can be a transformation or a job. Name these folders exactly the same as the job/transformation you want to test (just without the file extension). Each process folder must have an input and output folder which hold the DDL, Kettle data type definitions and in case of the output the sort order definition (see tr_category_sales sample on how to set this up). If your output dataset does not require any sorting, create an empty sort def file (see tr_fact_sales example). Note that KTF can handle more than one output/input dataset.
- The process folder must also contain at least one test case folder (which has to have a descriptive name). In the screenshot above it is called “simpletest”. A test case folder must contain an input and output folder which each hold the dedicated datasets for this particular test case. In case of the output folder it will hold the golden output dataset(s) (so that dataset that you want to compare your ETL output results to).
- Users working on Windows: For all the CSV output steps in transformations under /repository/test set the Format to Windows (Content tab). KTF has not been tested at all on Windows, so you might have to make some other adjustments as well.
- Add environment variables defined in config/set-project-variables.sh to your .bashrc. Then run: source ~/.bashrc
- Start Spoon (this setup requires PDI V5) or run the process from the command line.
- Run the test suite
- Analyze results in tmp folder. If there is an error file for a particular test case, you can easily visually inspect the differences like this:
dsteiner@dsteiner-Aspire-5742:/tmp/kettle-test/tr_category_sales/sales_threshold$ diff fact_sales_by_category.csv fact_sales_by_category_golden.csv
2c2
< 2013-01-01;Accessories;Mrs Susi Redcliff;399;Yes
---
> 2013-01-01;Accessories;Mrs Susi Redcliff;399;No
5c5
< 2013-01-02;Groceries;Mr James Carrot;401;No
---
> 2013-01-02;Groceries;Mr James Carrot;401;Yes
All files related to testing (KTF) are stored in repository/test. You should not have to alter them unless you find a bug or want to modify their behaviour.
To get a better idea on how this is working, look at the included examples, especially tr_category_sales (has multiple inputs and outputs and proper sorting). The other example, tr_fact_sales has only one output and input and no sorting defined (as it only outputs one figure).
Future improvements
Following improvements are on my To-Do list:
- Write test results to dedicated database table
- Improvement of folder structure
- Support for text file input and output for main processes (jobs/transformations)
FAQ
My input data sets come from more than one data source. How can I test my process with the KTF?
Your process must have parameter driven database connections. This way you can easily point your various JNDI connections to just one testing input database. The main purpose of testing is to make sure if the output is as expected, not to test various input database connections. Hence for testing, you can “reduce” you multiple input connections to one.