Experimenting with new layout features in PRD
Note: This article will cover features that are still in development. We take a first look at them, do not expect them to be feature complete and do not use them in production.All layouting strategies mentioned in this blog post are available for download here.
To experiment with the new features yourself, download the latest PRD build from http://ci.pentaho.com/
Place data rows next to each other
The standard detail layout places one row below the other:
Our sample dataset:
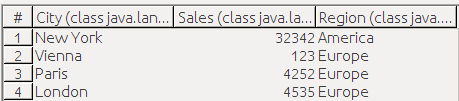
We set up Region as a group. Our report looks like this:
The report preview looks like this:

Compare the preview with the dataset above: You will see that a new details row was created for each group, and that the data rows were placed next to each other.
You can implement this the following way:
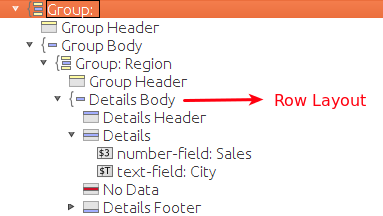
Simply select the Details Body in the Structure tab and in the Style tab set layout to row:
Make the group header part of the details section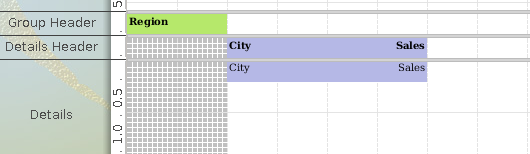
And here is how the preview of the report looks: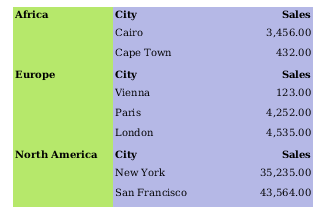
And here is how you can implement this layout:

Set the layout type as shown above for each band. Here an example for the Group:
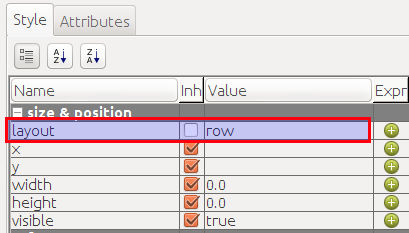
Note: Currently you cannot set the elements within the group header to 100%, but it will be possible in future. I implemented a workaround by using a formula to dynamically increase the size of the header element to whatever height the details band and header are consuming.
Table Layout
Although the table layout has been available in the trunk version of PRD for some time (see Thomas’ original blog post), there has hardly anything been written about it.The table layout available currently is mainly aimed at driving the crosstabs - nevertheless we can have a look at experimenting a bit with it. There is also no wizard or easy GUI available for to create a table [but there is one for crosstabs], so it is not that straightforward to create a table. Also it helps, if you are familiar with the HTML table layout.
Note also, that although you can create tables via the GUI, it is currently not possible to adjust the column widths individually. You can give the first column a specific width and all the other columns will automatically have the same width applied.
As you see, it is a start of having something similar to a table available within PRD. Current efforts of the PRD development team are mainly focused on finishing the cross tabs functionality and any table specific features will have to come after this. This doesn’t stop you though from submitting requests to jira.pentaho.org.
So now lets have a look how a table can be possibly created (info kindly provided by Thomas):
table-header, table-body and table-footer are all variations of a table-body. You will also need table-rows and table-cells to make it work properly.
I would do it in the following way:
group: table
group-header: table-header
+ subband for table-row
(child elements will be automatically wrapped into a table-cell)
details-body: table-body
itemband: table-row
group-footer: table-body
(table-footer is not implemented. But if it were, then the table requires it to follow directly after the table-header. See HTML standard for reference.)
I managed to get it working the following way:
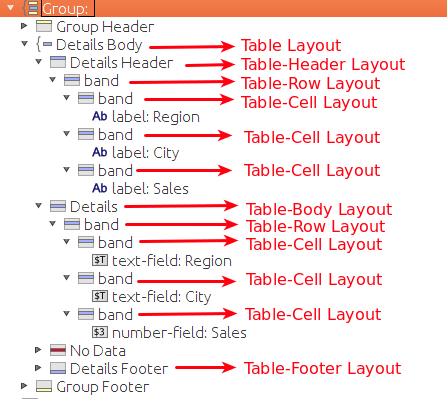
I added the extra band element with a table-cell layout to get this working, which normally should not be necessary - this a known bug.
The report looks like this in preview:

I hope you enjoyed seeing some new layouting features of PRD in action. Although they are not ready yet for production, it at least gives you some new ideas what you will be able to do in future.













