How to work with MapReduce Key Value Pairs in Pentaho Data Integration
My main objective for this article is to provide you an understanding on how to use multiple fields to group by and multiple fields to aggregate on in Pentaho PDI MapReduce.
The input key for the mapper is auto-generated, the value is usually the line of text which is read in (fields separated by comma in example). This section here will focus on the output key value pair of the mapper and input and output key value pair of the reducer. Also we will not discuss the simple scenario where we only use one field for the key and one field for the value.
I have more than one key field. How do I set up a compound key?
You are aware that the input and output of the mapper and reducer are key value pairs. If you haven’t been exposed that much to the internals of MapReduce and come more from a traditional ETL world, this is probably one of the most important concepts to understand.
Did you ever run a Hive query? Did you have to worry about the key fields … no. Hive is doing quite some work in the background … which some users are never exposed to. So when you come to PDI and create the key for your mapper and reducer transformations, the important point is that you have to separate the fields that form the key by the standard separator of the specified output format of the MapReduce job. If you chose the output format org.apache.hadoop.mapred.TextOutputFormat, tab is the standard separator.
Option 1: Thankfully Pentaho introduced not too long ago a step to just do this in an easy fashion: Use the new Concat Fields step (Wiki entry). This step allows you to create a new field based on several concatenated source fields which are separated by a character of your choice, such as a tab. If you specified the org.apache.hadoop.mapred.TextOutputFormat in the Pentaho MapReduce job entry as output format, tab is the standard separator.
“4.4.0 release note: Unfortunately we found an issue (PDI-8857) with this step that was too late to incorporate into 4.4.0. The step adds carriage return and line feed to the fields it creates. Workaround is to use the String operations step with the option "carriage return & line feed" after the step or to enable the advanced option "Fast data dump (no formatting)"
Option 2: Use a User Defined Java Expression step. This option was mainly used before the Concat Fields step was available. Generate the output key by writing some Java expression which concatenates the fields you want to group by.
Separate the fields with a tab in the concatenate output key, in example:
date + '\t' + brand
Important: Replace the tab with a real tab! So it should look like this then:
date + ' ' + brand
This way, all the fields will be properly separated in the final output. Tab in this case is the standard separator of org.apache.hadoop.mapred.TextOutputFormat.
I have more than one value field. How do I create a compound values field?
What if I want more than one value to aggregate on?
Create a new field i.e. called output_values in a Concat Fields or User Defined Java Expression step in the mapper transformation and concatenate all the values and define the separator. Then in the reducer split these values (use the Split Fields step), next aggregate them (use the Group By step) and after this you have to concatenate them again (use the Concat Fields step).
Let’s walk through a very simple example. We have some sales data which we want to analyze. Let’s say we want the sum of sales and a count of rows by date and brand.
The Kettle job:

Our input data for the Pentaho MapReduce job looks like this (date, brand, department, sales):
$ hadoop fs -cat /user/dsteiner/sales-test/input/sales.txt
2013-04-01,SimplePurpose,Clothes,234.2
2013-04-01,SimplePurpose,Accessories,2314.34
2013-04-01,RedPride,Kitchen,231.34
2013-04-02,SimplePurpose,Clothes,453.34
2013-04-01,SimplePurpose,Accessories,5432.34
2013-04-01,RedPride,Kitchen,432.23
2013-04-03,RedPride,Kitchen
The mapper transformation (simple example):

If we want to inspect what the output of the mapper transformation looks like, we can just simply execute the Pentaho MapReduce job entry without specifying a reducer.
Output of mapper - Note the key is formed by the first two fields which are separated by a tab and the value is formed by the sales and count field separated by a comma:
$ hadoop fs -cat /user/dsteiner/sales-test/output/part-00000
2013-04-01 RedPride 231.34,1
2013-04-01 RedPride 432.23,1
2013-04-01 SimplePurpose 234.2,1
2013-04-01 SimplePurpose 2314.34,1
2013-04-01 SimplePurpose 5432.34,1
2013-04-02 SimplePurpose 453.34,1
2013-04-03 RedPride ,1
The reducer transformation (simple example):
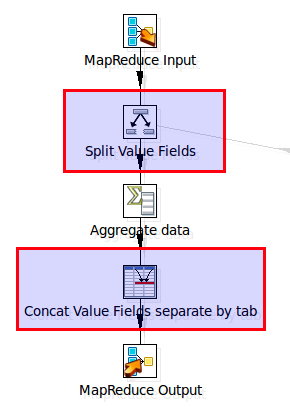
Our output data looks like this (date, brand, sum of sales, count):
$ hadoop fs -cat /user/dsteiner/sales-test/output/part-00000
2013-04-01 RedPride 663.57 2
2013-04-01 SimplePurpose 7980.88 3
2013-04-02 SimplePurpose 453.34 1
2013-04-03 RedPride 0 1
So you can see that we successfully managed to aggregate our data by date and brand and sum up the sales as well as perform a count on the rows.
It’s best if you take a look at my sample files (which you can download from here) to understand all the details. I hope that this brief article shed some light onto creating key value pairs for the Pentaho MapReduce framework.
Awesome as usual!
ReplyDeleteMany thanks for your feedback!
Delete